译注:本文翻译自 ChromeDeveloper 博客, 原文发表于2018年底, 部分特性可能与目前 Chrome 有所不同。建议有条件的读者直接阅读原文。
本文是深入理解现代浏览器4章中的第2章。此前我们研究了不同进程和线程是如何处理浏览器的不同部件的, 本章中, 我们来深挖每个进程和线程间是如何通信以显示网站的。
我们来看一个简单浏览器网站的用例:在浏览器中输入URL, 然后浏览器从网络上获取数据并显示页面。本章中, 我们聚焦于用户请求站点并准备呈现页面这一部分--即我们说的导航(Navigation)。
从浏览器进程开始说起

browser 进程
如我们之前所说,标签以外的所有内容都由 browser 进程处理。browser 进程拥有很多线程, 像绘制按钮和输入域的 UI 线程,和网络栈交换信息以从网上接收数据的 network 线程,控制文件访问的 storage 线程等等。当你在地址栏输入URL时, browser 进程的 UI线程会处理你的输入。
简单的导航
Step 1: 处理输入
当用户开始在地址栏中输入时,UI线程首先会问"这是一搜索查询还是URL"。 在Chrome 中, 地址栏也是搜索输入域,所以UI线程需要解析并确认是使用搜索引擎还是请求站点。
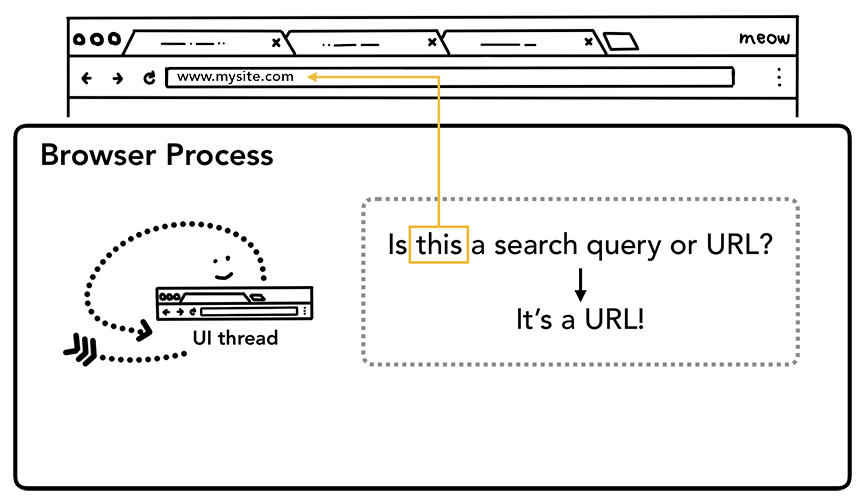
UI 线程询问输入的是搜索还是 URL
Step 2: 开始导航
当用户点击回车,UI 线程启动一个网络调用并获取站点内容。标签的左上角会显示加载动画,并且 network 线程这通过适当的协议来处理请求, 如 DNS查找与TSL连接建立。
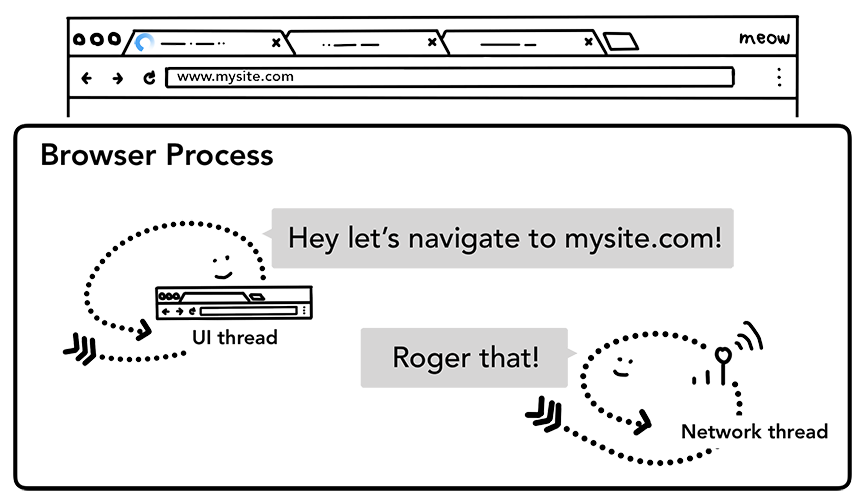
UI 线程告诉 network线程, 要导航到 mysite.com
此时, network 线程可能收到像HTTP301 这样的服务重定向头。这种情况下, network 线程和UI线程交流, 服务请求重定向, 之后开始另一个URL请求。
继续阅读
译注:本文翻译自 ChromeDeveloper 博客, 原文发表于2018年底, 部分特性可能与目前 Chrome 有所不同。建议有条件的读者直接阅读原文。
本系列有4章, 我们将从高层架构到管道渲染的细节来深入理解 Chrome 浏览器。如果你想知道浏览器如何将你的代码变成功能性的网站, 或者你不确实为何被建议使用某种技术来提高网页性能, 那么本系列会适合你。
在本章中, 我们将了解核心计算的术语及Chrome 的多进程架构。
计算机的核心是 CPU 和 GPU
为了理解浏览器运行的环境, 我们需要理解一些计算机部分及它们的作用。
CPU

首先是 中央处理单元(CPU) , CPU可以比作你计算机的大脑。一个CPU核心,就如图中的一个办公室职员, 可以一一处理很多不同的任务。它可以处理从数学到文艺的所有的事件, 甚至知道如何答复客户。过去大部分CPU是单芯的。而核就像生活在同一个CPU中的另一个芯片。在现代硬件中,你通常拥有多核CPU,它为你的手机和笔记本提供更多算力。
GPU
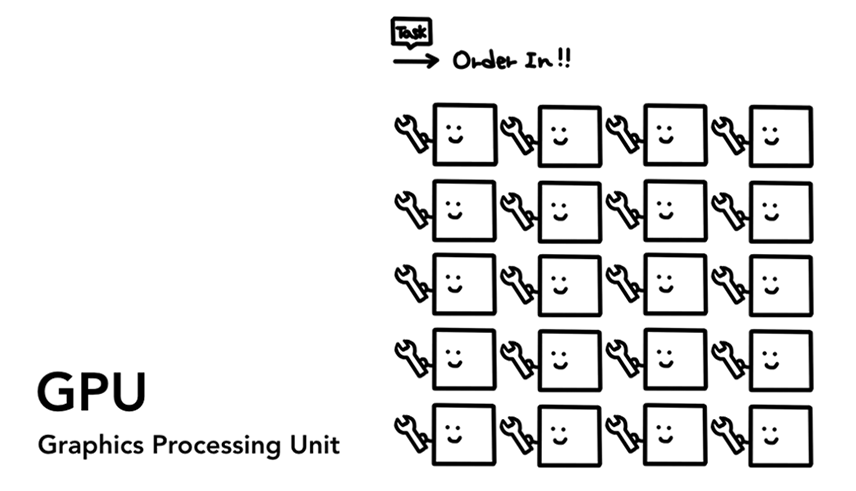
图像处理单元(GPU) 是计算机的另一个部件。和CPU不同的是,GPU擅长处理简单任务, 不过它可以同时跨越多核。顾名思义, 它最初是为处理图像而开发。这就是为何在图形上下文中, "使用GPU" 或 "GPU支持" 往往与快速渲染和平滑交互相关联。现如今, 随着GPU加速运算的发展,越来越多仅在GPU上完成的运算成为可能。
当你在电脑或手机上启动程序时, CPU和GPU都为程序提供算力。通常程序使用操作系统提供的机制在CPU和GPU中运行。
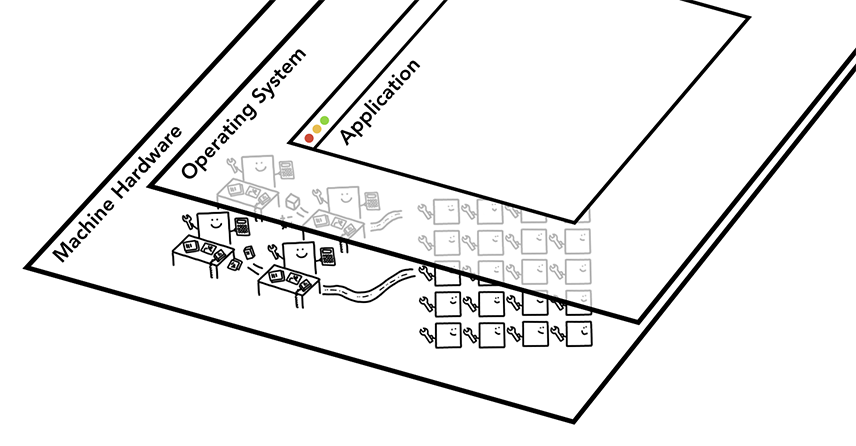
在进程和线程中执行程序
在深入研究浏览器架构之前要掌握的概念是进程和线程。进程可以看作是应用程序的执行程序。而线程存在于进程内部执行其进程程序任意部分。
继续阅读
如下两个结构体 A B ,他们的实例的大小相同吗?
|
|
struct A{ char c_1; int i; char c2; }; struct B{ char c_1; char c_2; int i; }; |
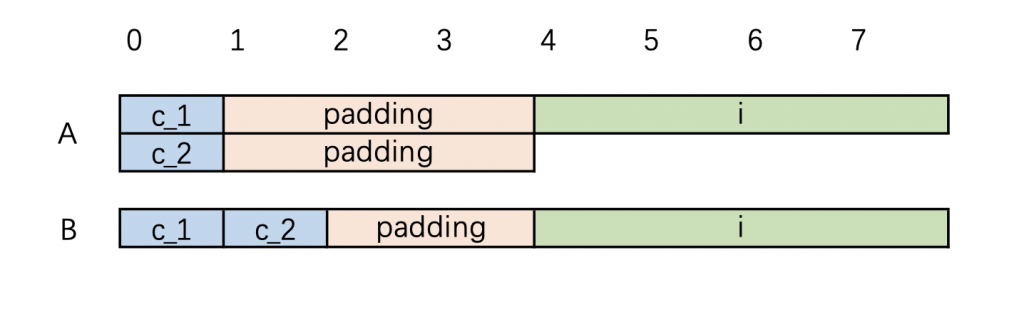
两个 char 共占两个字节, 一个 int 占4个字节, 所以两个结构体都是 6个字节。但事实并非如此,在大部分计算机中,他们都不会只占 6 个字节。这涉及到 内存对齐
需知,计算机访问内存的方式,并不是一个字节一个字节访问的,而是以字长(word size)为单位来进行访问的。32位计算机的字长为 4 字节, 64位计算机的字节为 8 字节。而所谓内存对齐, 就是将变量调整至字长的倍数的位置存放,以方便计算机访问。
上面两个结构体在内存中的布局最有可能是这个样子的:(这里说 最有可能 是因为具体的布局要视计算机而定)
我们使用一段代码来验证:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
void showmem(unsigned char* p, uint32_t sz){ int len = sizeof(int*); cout<<"\t"; for(int i = 0; i<len; i++){ cout<<i<<"\t"; } cout<<endl; for(int i = 0; i<=len; i++){ cout<<"-------|"; } cout<<endl; unsigned char* t = p; uint32_t i = 0; char msg[8]; while(i < sz){ sprintf(msg, "%02d", i); cout<<msg<<"|\t"; for(int j = 0; j< len && (i+j)<sz; j++){ sprintf(msg, "%04d", *(uint8_t*)(t+j)); cout<<msg<<"\t"; } cout<<endl; i += len; t += len; } } //// //... A a{'a', 2, 'b'}; B b{'a', 'b', 2}; cout<<"A:"<<endl; showmem((unsigned char*)&a, sizeof(a)); cout<<endl; cout<<"B:"<<endl; showmem((unsigned char*)&b, sizeof(b)); cout<<endl; |
结果如下:
|
|
A: 0 1 2 3 4 5 6 7 -------|-------|-------|-------|-------|-------|-------|-------|-------| 00| 0097 0000 0000 0000 0002 0000 0000 0000 08| 0098 0000 0000 0000 B: 0 1 2 3 4 5 6 7 -------|-------|-------|-------|-------|-------|-------|-------|-------| 00| 0097 0098 0000 0000 0002 0000 0000 0000 |
在 A 中,c_1 i 共占一个字,c_2 占一个字。这种将多个变量放入一个字中的动作,叫作 packing 。 而组成一个字时,补充不足的部分,叫 padding 。
如何知道某种类型的变量要对齐到哪个位置呢?它取决于一个类型的 alignment 如 int 类型的alignment 为4, 那么int 类型变量的地址必定为 4 的倍数。
继续阅读
在前一部分(从单例模式谈起(一))我们讨论单例模式时,谈到了 Double-Checked Locking 问题。我们讲, volatile 关键字并不能解决Double-Checked Locking 问题。这一节我们讨论与此相关的问题。
现代编译器为了提高程序的效率而对代码做了很多优化。这些优化大部分是有益的,但是也为多线程编程带来问题。
寄存器缓存
我们来看如下代码:
|
|
x = 0; Thread1 { lock(); x++; unlock(); } Thread2 { lock(); x++; unlock(); } |
x++ 的值有锁保护,所以它是独占的,x++ 的行为不会被并发破坏。那么 x 的值必然为 2。 然而现实中并非一定如此:编译器有可能为了提高 x 的访问速度而将 x 放入线程的某个寄存器中,而线程的寄存器是线程私有的。 如果 Thread1 先获得了锁,那么程序的执行过程有可能是这样的:
- [Thread1] 读取 x 到寄存器 R1. (R1 = x = 0)
- [Thread1] R1++. unlock. 由于之后可能还会访问 x, 所以 Thread1 不将 R1 写回 x . (x = 0)
- [Thread2] 读取 x 到寄存器 R2 (R2 = x = 0)
- [Thread2] R2++
- [Thread2] 将 R2 写回 x (x = R2 =1)
- [Thread1] 在某个时候将 R1 写回 x (x = R1 = 1)
由此可见,即使正确的加了锁,也不能保证多线程安全。
继续阅读
什么是 Coredump
coredump 核心转储 ,也称为 核心文件(core file) 是操作系统在进程收到某些 信号 而终止运行时,将此进程的地址空间以内容以及有关进程状态的其他信息写出的一个文件。这种信息往往用于调试。
程序员可以通过工具来分析程序运行过程中哪里出错了:Windows 平台用 userdump 和 WinDBG ,Linux 平台使用gdb, elfdump, objdump 等
Windows WinDBG
关于 windbg, 可以参考以下资料
Linux GDB
有些时候进程在crash的时候会产生 core 文件, 但我们却找不到 core 文件,我们需要使用 ulimit 进行一些设置, 这个命令是用来限制系统用户对shell资源的访问的。
ulimit -a 可以查看当前的设置
ulimit -c 可以设置 core 文件的上限,单位为区块(一般 1 block = 512 bytes) .其值为 0 时不写入 core, 为 unlimited 时不限制 core 文件大小。
需要注意, ulimit 只对当前会话有效。若想对所有会话生效, 需要在 /etc/profile 中进行配置。
源文件如下 test_vec.cpp :
|
|
#include <iostream> #include <vector> using namespace std; int main(){ std::vector<int> v{42}; cout<<v.at(5)<<endl; //Will crash, and coredump return 0; } |
编译运行时可能出现如下现象:
|
|
$ g++ -o t_vec ./test_vec.cpp $ ./t_vec terminate called after throwing an instance of 'std::out_of_range' what(): vector::_M_range_check: __n (which is 5) >= this->size() (which is 1) Aborted (core dumped) |
使用 gdb 打开来看:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
$ gdb t_vec core Core was generated by `./t_vec'. Program terminated with signal SIGABRT, Aborted. #0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:51 51 ../sysdeps/unix/sysv/linux/raise.c: No such file or directory. (gdb) i s #0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:51 #1 0x00007fbe77c7f801 in __GI_abort () at abort.c:79 #2 0x00007fbe782d4957 in ?? () from /usr/lib/x86_64-linux-gnu/libstdc++.so.6 #3 0x00007fbe782daab6 in ?? () from /usr/lib/x86_64-linux-gnu/libstdc++.so.6 #4 0x00007fbe782daaf1 in std::terminate() () from /usr/lib/x86_64-linux-gnu/libstdc++.so.6 #5 0x00007fbe782dad24 in __cxa_throw () from /usr/lib/x86_64-linux-gnu/libstdc++.so.6 #6 0x00007fbe782d6855 in ?? () from /usr/lib/x86_64-linux-gnu/libstdc++.so.6 #7 0x000055a4f8cda08a in std::vector<int, std::allocator<int> >::_M_range_check(unsigned long) const () #8 0x000055a4f8cd9e9d in std::vector<int, std::allocator<int> >::at(unsigned long) () #9 0x000055a4f8cd9c11 in main () (gdb) |
从 gdb显示的栈信息来看,崩溃发生在 main 函数内的 vector::at 函数内,由 _M_range_check raise 。
如果我们在编译时使用了 -g 选项, 会得到更详细的信息
继续阅读
1. 调试宏
宏是预编译的,无法 print 宏的定义。但是如果配合 gcc, 我们还是可以有限地调试宏。
在 GCC 编译程序的时候,加上 -g3 参数,就可以调试宏了。
info macro mac_name 可查看宏定义,及位置macro expand mac_expr 可查看宏展开的样子
示例:
|
|
#include <iostream> using namespace std; #define MY_ADD(a,b) (a * 2 + b) #define M 42 #define DM(x) (M+x) int main(){ int s = MY_ADD(2,3); cout<<s<<endl; cout<<DM(s)<<endl; return 0; } |
调试现场如下:
|
|
(gdb) i macro M Defined at /home/zr/code/use_gdb/src3/./test_macro.cpp:5 #define M 42 (gdb) macro expand DM(1) expands to: (42+1) |
2. 修改变量
两种方法:
print var_name=xset var var_name=x
示例:
继续阅读
命令
GDB 是 Linux 下的命令行调试工具。
启动 GDB 有如下几种方式:
gdb <program> 直接启动执行程序gdb <program> core 用gdb 同时调试一个可执行程序和core文件。core 是程序非法执行后 core dump 产生的文件gdb <program> <PID> 指定进程, gdb会自动 attach 上去。program 应该在 PATH 环境变量中可以搜索得到。
常用的 gdb 命令如下
信息 info
info 可以简写成 i
info args 列出参数info breakpoints info break i b 列出所有断点info break number i b number 列出序号为 number 的的断点info watchpoints i watchpoints 列出所在 watchpointsinfo threads 列出所有线程inifo registers 列出寄存器的值info set 列出当前 gdb的所的设置i framei stacki localsi catch
断点和监视 break & watch
继续阅读
Cookie 指某些网站为了辨别用户身份而储存在用户本地终端(Client Side)上的数据,它是一种古老的技术, 由网景公司的前雇员卢·蒙特利在1993年3月发明。
Cookie 格式是一系列键值对, 以 ; 组合,如下
|
|
TBLkisOn=0; GeoIP=US:CA:Los_Angeles:34.05:-118.26:v4; mwPhp7Seed=9d0 |
当然, Cookie还有更多的内容,如创建时间,过期时间等,对应的域等等。一般而言,为了安全只允许页面访问该域下的Cookie.
根据 Cookie 的时效性可以将 Cookie 分为两类,一种是会话型Cookie (Session Cookie), 只保存于内存中, 当浏览器退出的时候,即清除这些 Cookie. 第二种是持续型 Cookie (Persistent Cookie),也就是当浏览器退出的时候仍然保留的Cookie.
Chromium 中Cookie操作的类结构如下所示: 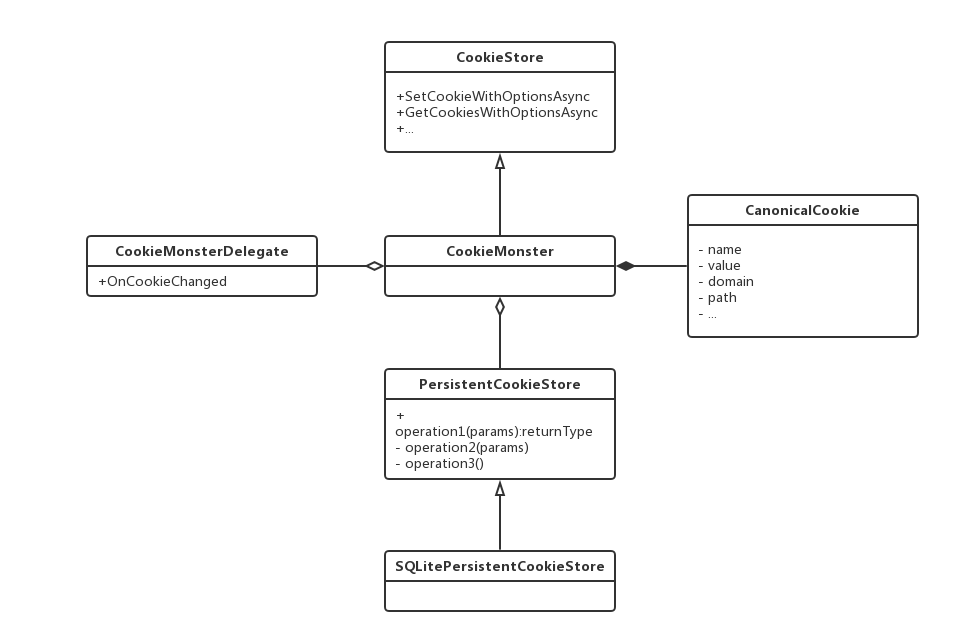
其中 CookieStore 是主要的导出接口,CookieMonster 是重要的实现接口,它相当于是 Cookie 的管理器。它有几个作用:一是实现 CookieMonster 中的接口,二是报告前者的事件,如 Cookie 更新信息等,三是 Cookie对象(即 CanonicalCookie) 的集合。
PersistentCookieStore 持久化类,SQLitePersistentCookieStore 是持久化的具体实现,负责实际的存储动作。
Chrome 的 Cookie使用 Sqlite存储,是位于 %AppData%\Local\Google\Chrome\User Data\Default 目录下的 Cookies 文件。
继续阅读