Blink 是如何工作的
目录
TL;NR
在 Blink 上开发绝非易事。对于新接触 Blink的开发者来说,要实现一个高效的渲染引擎,需要了解大量Blink特有的概念和编码约定。对于经验丰富的开发者来说亦非易事,因为 Blink 非常庞大,对性能、内存和安全性极为敏感。
本文从全局概述了 "Blink 是如何工作的",希望有助于开发者快速熟悉Blink的架构:
- 本文并非Blink详细架构与编码规范的开发手册(这些内容可能会变化或过时)。相反地,本文简明扼要地介绍了短期内不会变更的Blink基本原理,并提供了可以进一步阅读的资源(如果你想了解更多的话)
- 本文不解释特定功能(e.g. ServiceWorkers, editing),相反地,本文解释了代码中广泛使用的基本功能(e.g. 内容管理, V8 APIs).
关于Blink开发的更多内容, 参考这里 Chromium wiki page
Blink 做了什么
Blink 是web平台的渲染引擎。简单地说,Blink 实现了浏览器 tab 内的所有内容的渲染:
- 实现web平台规范(e.g HTML标准),包括 DOM, CSS, WebIDL
- 内嵌 V8,并执行 JavaScript
- 向底层网络栈申请资源
- 构建 DOM 树
- 计算样式与布局
- 内嵌 Chrome Compositor,并绘图
通过 content public APIs , 很多客户端嵌入了 Blink, 如 Chromium, Android WebView, Opera 等.

从代码的角度来看,Blink 即 //third_party/blink/ ;从工程(project)的角度来看,Blink 即实现Web平台功能的工程。实现Web平台功能的代码分布在 //third_party/blink/, //content/renderer/, //content/browser/ 及其它地方。
进程/线程架构
进程
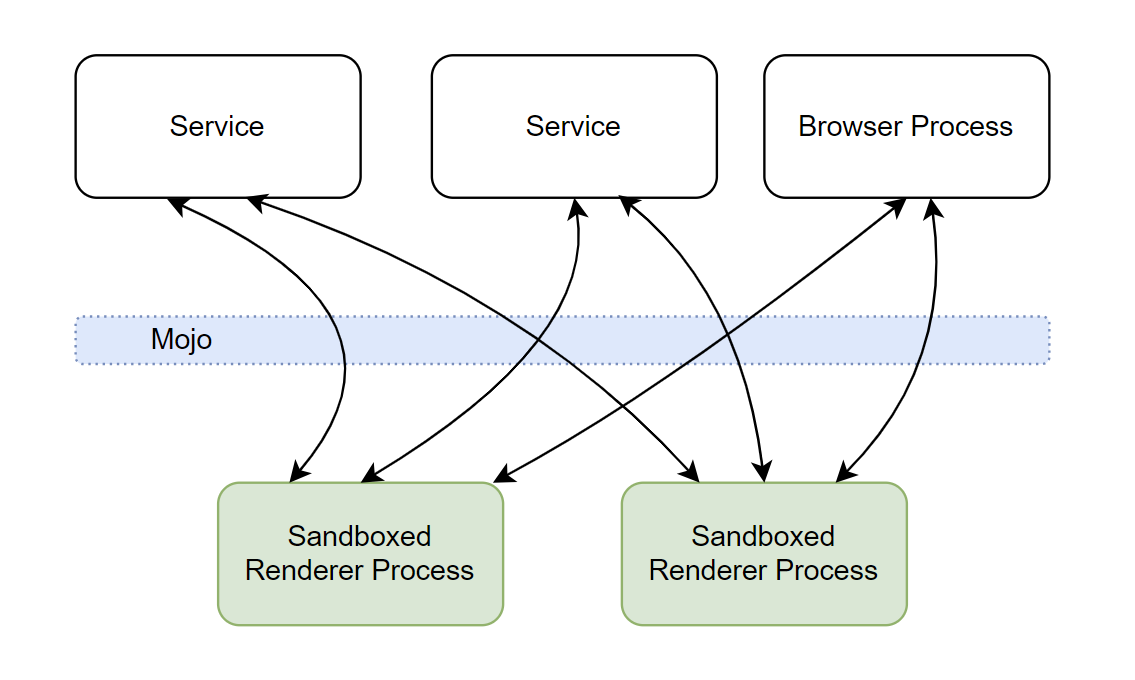
Chromium 是多进程架构的。它有一个 浏览器进程(browser process) 与 N 个沙盒化的 渲染进程(renderer process),Blink 运行在 渲染进程中。
那么,N 是多少呢?为安全计,跨站点 documents 间的内存地址隔离非常重要(即站点隔离 Site Isolation)。 理论上讲,一个 渲染进程最多只应该用于一个站点。而事实上,当用户打开了太多的 tab ,或者没有足够的内存时,对 渲染进程与站点做一对一的限制就显得很繁重了。所以,多个 iframe 或从不同站点加载的 tab 可能会共享同一个渲染进程。这意味着一个 tab 内的 iframe 可能在不同的渲染进程中,而不同 tab 内的 iframe 可能在一个渲染进程中。渲染进程,iframe 与 tab 之间不存在 1:1 的映射关系。
对于一个运行在沙盒中的渲染进程, Blink 需要向浏览器进程派发系统调用(e.g. 访问文件,播放媒体),以及访问用户数据(user profile data, e.g. cookie, passwords)。 这种 浏览器-渲染 进程间的通信是基于 Mojo 的(过去使用的是 Chromium IPC, 目前仍有一些地方在使用它,但该方式已被弃用)。在 Chromium 中正在进行服务化(Servicification),并将浏览器进程视为一组 "服务" 的集合。从 BlinK 的角度来看,它只需要使用 Mojo 与服务和浏览器进程交流。
若想了解更多:
- 多进程架构
- Blink 中的 Mojo 编程
线程
一个渲染进程会创建多少个线程呢?
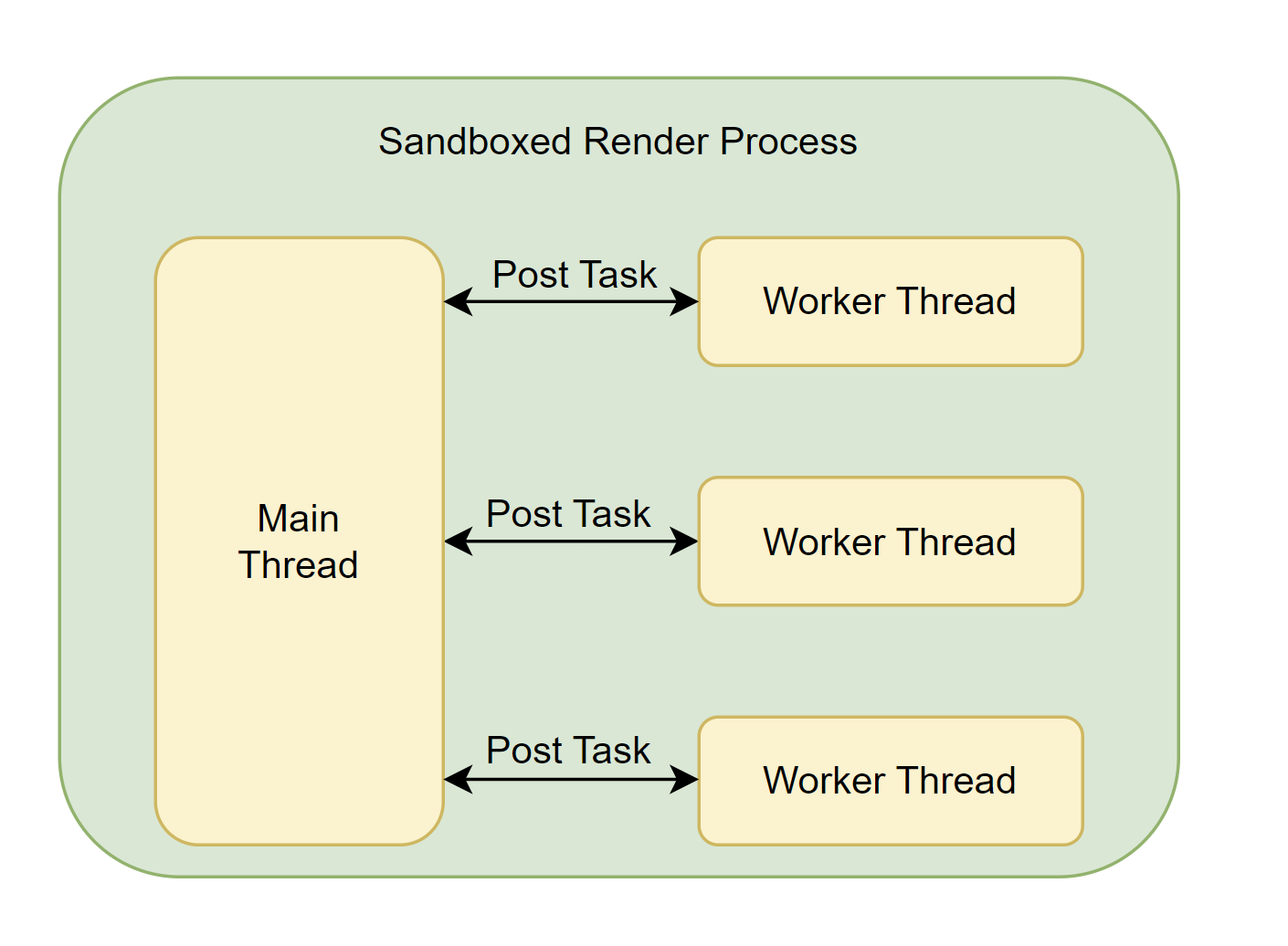
Blink 有一个主线程(main thread), N 个工作线程(worker thread) 以及一堆内部线程(internal thread)。
几乎所有重要的事件都发生在主线程内: 所有的JavsScript(workers 除外),DOM, CSS, 样式与布局计算都运行在主线程内。Blink 经过高度优化以使主线程性能最大化。
Blink 会创建多个工作线程以运行 Web Workers, ServiceWorkers 以及 Worklets.
Blink 及 V8 会创建多个内部线程来处理 网络音频、数据库、GC 等。
对于进程间通信,你必须使用 PostTask APIs 来传递消息。除非个别地方出于性能原因,我们不鼓励使用共享内存编程。这就是为什么你很少在 Blink 代码内见到互斥锁。
若想了解更多:
- Blink 中的线程编程: platform/wtf/ThreadProgrammingInBlink.md
- Workers
Initialization & finalization
Blink 使用 BlinkInitializer::Initialize() 初始化。它必须在任何 Blink 代码调用前执行。
但 Blink 从不终结化(finalized). 比如,渲染进程会不做清理而强制退出。这一方面是基于性能原因。另一方面,优雅有序地完全清理渲染进程的内容是真的难(也不值这么做)。
目录结构
Content public API 以及 Blink public API
Content public API 是使程序能嵌入渲染引擎的 API 层。它是暴露给其它程序的API, 须小心维护。
Blink public API 是 //third_party/blink/ 向 chromium 提供功能的 API 层。这是从Webkit 继承而来的 API. 在 Webkit 时代,Chromium 和 Safari 共享 Webkit, 所以这些API 需要向 Chromium 和 Safari 提供功能,而现在 //third_party/blink/ 只有 Chromium 在用,所以它不再重要了。我们现在正在消减 Blink public API, 将 web平台的代码从 Chromium 移到 Blink 中(即 "Onion Soup Project")
目录结构及依赖
//third_party/blink 有如下目录:
platform/: Blink 底层功能的集合,它们是从core/中分离出来的, e.g. geometry 与 graphics utilscore/与modules/: 所有 web 平台的功能实现都在这里。core/实现了与 DOM 紧耦合的功能,modules/则实现了更多自包含的功能, e.g. webaudio, indexedBDbindings/core/与bindings/modules/: 理论上bindings/core/是core/的一部分,bindings/modules/是modules/的一部分。重度使用 V8 API 的文件放在这里controller/: 使用core/与modules/的上层库。 e.g. devtools 前端。
这个文档有更详细的介绍
依赖顺序如下:
- Chromium
controller/modules/与bindings/modules/core/与bindings/core/platform/- 底层单元, 如
//base,//v8以及//cc
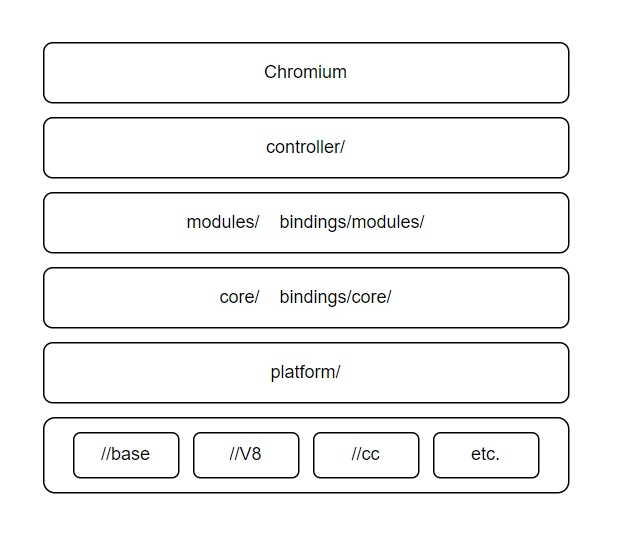
Blink 小心地维护着暴露给 //third_party/blink 的底层单元。
若想了解更多:
WTF
WTF 是 Blink 专用的 base 库, 其位于 platform/wtf/ 。我们尽可能地统一 Chromium 与 Blink 的编码,所以 WTF 库应该很小。此库之所以存在,是因为确实需要一批 类型、容器及宏 来对 Blink 的工作量与 Oilpan(Blink 的 GC)进行优化。如果在 WTF 中有某个类型的定义,Blink 就必须使用 WTF 中的而非 //base 或 std 库中定义的类型。最常用的一些是向量(vector)、哈希集合(hashset)、哈希映射(hashmap)与字符串(string)。 Blink 应该使用 WTF::Vector WTF::HashSet, WTF::HashMap WTF::String 与 WTF::AtomicString, 而不是 std::vector , std::*set , std::*map 与 std::string
若想了解更多:
内存管理
在 Blink 中, 你需要关注三个内存分配器:
- PartitionAlloc
- Oil Pan (a.k.a. Blink GC)
- malloc/free 和 new/delete (已ban)
可以通过 USING_FAST_MALLOC() 在 PartitionAlloc 的堆上分配对象:
|
1 2 3 4 5 6 |
class SomeObject { USING_FAST_MALLOC(SomeObject); static std::unique_ptr<SomeObject> Create() { return std::make_unique<SomeObject>(); // Allocated on PartitionAlloc's heap. } }; |
PartitionAlloc 分配的对象的生命周期应该用 scoped_refptr<> 或 std::unique_ptr<> 来管理。 强烈不建议手动管理其生命周期。在 Blink 中手动 delete 已被禁用。
可以使用 GarbageCollected 在 Oilpan 的堆上分配对象:
|
1 2 3 4 5 6 |
class SomeObject : public GarbageCollected<SomeObject> { static SomeObject* Create() { return new SomeObject; // Allocated on Oilpan's heap. } }; |
Oilpan 分配的对象的生命周期由垃圾回收器自动管理。必须使用指定的指针(e.g. Member<> Persistent<>)来存放 Oilpan 堆上的对象。参 阅此API参考 来熟悉 Oilpan 的编程规范。最最重要的规范,是不允许在一个 Oilpan 对象的析构器内访问任何其它的 Oilpan 对象(因为销毁顺序没有保证)。
如果不使用 USING_FAST_MALLOC() 或 GarbageCollected ,那么对象就被分配在系统的 malloc 上。在Blink 中强烈不建议这种行为。所的有 Blink 对象都应该使用 PartitionAlloc 或 Oilpan 分配,规则如下:
- 默认使用 Oilpan
- 仅有以下情况使用 PartitionAlloc :
- 对象的生命周期很清晰,使用
std::unique_ptr<>或scoped_ptr<>就已够用的 - 在 Oilpan 上分配对象会带来复杂性的
- 在 Oilpan 上分配对象会给垃圾回收器带来很多不必要的压力的
- 对象的生命周期很清晰,使用
不管是使用 PartitionAlloc 还是 Oilpan, 都必须注意不要创建悬空指针(注:强烈不建议使用裸指针)或内存泄漏。
若想了解更多:
任务调度
为提高渲染引擎的响应性,Blink 中尽可能地使用异步的任务。同步的 IPC/Mojo 及其它操作会耗时数个毫秒, 所以不建议使用(尽管有些情况不可避免,e.g. 用户执行 JavaScript)。
渲染进程中的所有任务,都应该使用合适的任务类型抛到 Blink 调度器(Scheduler) 中,比如:
|
1 2 |
// Post a task to frame's scheduler with a task type of kNetworking frame->GetTaskRunner(TaskType::kNetworking)->PostTask(..., WTF::Bind(&Function)); |
Blink 调度器维护多个任务队列,能够智能地安排任务以使用户体验上的性能最大化。为使调度器正确地且智能地安排任务,指定 合适的任务类型 就显示尤为重要。
若想了解更多:
Page, Frame, Document, DOMWindow, etc.
概念
- 一个 Page 对应一个 tab(如果下面提到的 OOPIF 没有开启)。一个渲染进程可能包含多个 tab。
- 一个 Frame 对应一个 frame(mainFrame 或 iFrame)。每个 Page 包含一个或多个 树形排列的 Frame
- 一个 DomWindow 对应一个 JavaScript
window对象。每个 Frame 有一个 DOMWindow - 一个 Document 对应一个 JavaScript
window.document对象。每个 Frame 有一个 Document - 一个 ExcutionContext 对应一个 Document(对于 主线程)和 WorkerGlobalScope(对于 工作线程)的抽象
渲染进程 : Page = 1 : N
Page : Frame = 1 : M
Frame : DOMWindow : Document (or ExecutionContext) 总是 1 : 1 : 1 , 但映射的对象可能发生变化。比如考虑如下代码:
|
1 |
iframe.contentWindow.location.href = "https://example.com"; |
此种情况, 会为 "https://example.com" 创建新的 DOMWindow 和 Document, 而 Frame 可能会被复用。
(注:准确地说,某些情况下会创建一个新的Document, 但 DOMWindow 和 Frame 会被复用。参考 这些更复杂的情况 )
若想了解更多:
- core/frame/FrameLifecycle.md
进程外 iframe (Out-of-Process iFrame, OOPIF)
站点隔离使事情更安全,但也更复杂了。站点隔离的理念,是为每个站点创建一个渲染进程(一个站点,即一个注册域名 + 一个标签(子域名?), 以及它的 URL scheme, 例如 https://mail.example.com 和 https://chat.example.com 是同一个站点, 而 https://noodles.com 和 https://pumpkins.com 不是。) 如果一个 Page 包含一个跨站点的 iframe, 这个 Page 可能被两个渲染进程所托管。考虑如下 Page:
|
1 2 3 4 |
<!-- https://example.com --> <body> <iframe src="https://example2.com"></iframe> </body> |
mainFrame 与 iFrame 可能被不同的渲染进程托管。
渲染进程本地的 frame 用 LocalFrame 表示, 非渲染进程本地的 frame 用 RemoteFrame表示。
从 mainFrame 的角度来看,mainFrame 是 LocalFrame, iframe 是 RemoteFrame。 而从 iframe 的角度来看, manFrame 是 RemoteFrame, 而 iframe 是 LocalFrame。
LocalFrame 与 RemoteFrame 的通信(它们可能存在于不同的渲染进程) 是通过浏览器进程进行的。
若想了解更多:
- 设计文档
- 如何写站点隔离的代码:core/frame/SiteIsolation.md
Detached Frame/Document
Frame / Document 可能处于分离态。考虑如下情况:
|
1 2 3 |
doc = iframe.contentDocument; iframe.remove(); // The iframe is detached from the DOM tree. doc.createElement("div"); // But you still can run scripts on the detached frame. |
一个棘手的事实是,你仍然可以在分离的 frame 上运行脚本或 DOM 操作。由于 frame 已经分离,大多数 DOM 操作都会失败并出错。遗憾的是,分离 frame 上的行为在浏览器之间并不具有真正的互操作性,在规范中也没有明确定义。我们的期望是 JavaScript 应继续运行,但大部分 DOM 操作应该失败,并出现一些适当的异常,就像下面这样:
|
1 2 3 4 5 6 |
void someDOMOperation(...) { if (!script_state_->ContextIsValid()) { // The frame is already detached …; // Set an exception etc return; } } |
这意味着通常情况下,当 frame 被分离时,Blink 需要进行大量的清理操作。可以通过继承自 ContextLifecycleObserver 来做到这一点,就像这样:
|
1 2 3 4 5 6 7 8 |
class SomeObject : public GarbageCollected<SomeObject>, public ContextLifecycleObserver { void ContextDestroyed() override { // Do clean-up operations here. } ~SomeObject() { // It's not a good idea to do clean-up operations here because it's too late to do them. Also a destructor is not allowed to touch any other objects on Oilpan's heap. } }; |
Web IDL 绑定
当 JavaScript 访问 node.firstChild 时,node.h 中的 Node::firstChild() 被调用。我们来看看它是如何工作的。
首先, 你要在根据规范定义一个 IDL 文件:
|
1 2 3 4 |
// node.idl interface Node : EventTarget { [...] readonly attribute Node? firstChild; }; |
WebIDL 语法定义在 WebIDL规范 中. [...] 称为 IDL扩展属性。部分 IDL 扩展属性定义在 WebIDL 规范里,另一些定义在 Blink专用 IDL 扩展属性 中。 除 Blink 特有的 IDL 扩展属性外,IDL 文件应以符合规范的方式编写(i.e. 从规范中复制粘贴吧)
其次,你需要为 Node 定义一个 C++ 类,并为 firstChild 实现一个 getter
|
1 2 3 4 5 6 7 8 |
class EventTarget : public ScriptWrappable { // All classes exposed to JavaScript must inherit from ScriptWrappable. ...; }; class Node : public EventTarget { DEFINE_WRAPPERTYPEINFO(); // All classes that have IDL files must have this macro. Node* firstChild() const { return first_child_; } }; |
通常来讲就这些。在编译 node.idl 时, IDL 编译器 自动为 Node 接口和 Node.firstChild 生成 Blink-V8 绑定。代码生成在 //src/out/{Debug,Release}/gen/third_party/ blink/renderer/bindings/core/v8/v8_node.h 中。当 JavaScript 调用 node.firtChild 时, V8 调用 v8_node.h 中的 V8Node::firstChildAttributeGetterCallback() ,然后其调用你在前面定义的 Node::firstChild()
若想了解更多:
V8 和 Blink
Isolate, Context, World
在编写涉及 V8 API 的代码时,理解 Isolate、Context 和 World 的概念非常重要。在代码中,它们分别由 v8::Isolate 、v8::Context 和 DOMWrapperWorld 表示。
Isolate 与物理线程相对应。在Blink 中,Isolate : 物理线程 = 1 :1 。主线程有它自己的 Isolate, 工作线程也有它自己的 Isolate。
Context 对应一个全局对象(如果是 frame, 则是 frame 的 window 对象)。自从每个 frame 都有其自己的 window 对象,一个渲染进程中就有了多个 Context 。在你调用 V8 API 时,需要确保你在正确的 Context 中, 否则 v8::Isolate::GetCurrentContext() 将返回错误的 context 。在最坏的情况下它会导致内在泄漏,并引发安全问题。
World 是一个支持 Chrome Extension 的 content 脚本的概念。World 没有任何对应的 web 标准。Content 脚本希望与 web Page 共享 DOM, 但出于安全考虑,Content 脚本中的 JavaScript 必须与 web Page 中的 Javascript 堆隔离(isolate)。(同样, 两个 Content 脚本之间的 JavaScript 堆也应该隔离。) 为了实现隔离, 主线程会创建一个 main world, 而为每个 content 脚本创建隔离的 isolated world。这种隔离是通过为一个 C++ DOM 对象创建多个 V8 wrapper 实现的。 i.e. 每个 world 都有一个对应的 V8 wrapper
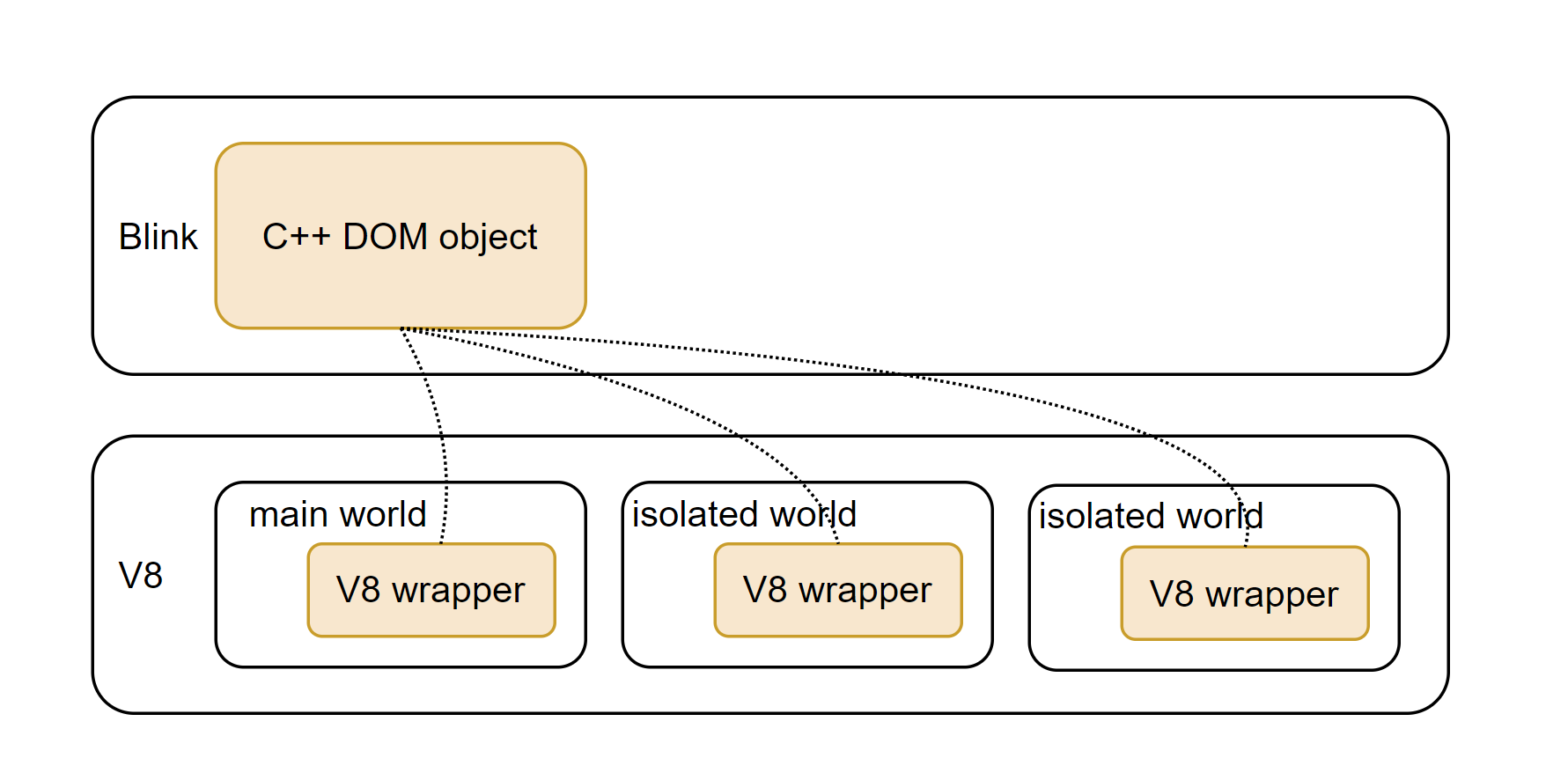
那么, context, world, frame 之间是联系是什么样的呢
假设在主线程里有 N 个 world (一个 main world + (N-1)isolated worlds)。那么一个 frame 应该有 N 个 window 对象, 每个对象使用一个 world . context 是与 window 对象对应的概念,这意味着,如果我们有 M 个 frame 和 N 个 world, 那么我们有 M * N 个 context (context 是延时创建的)。
对于 worker 来说, 只有一个 world 和一个全局对象, 所以也就只有一个 context
同样地,如果你用到了 V8 API, 你就要特别注意使用正确的 context, 否则会导致在隔离的 world 中泄漏 JavaScript 对象,并引发安全灾难。(e.g. A.com 的 extension 可以任意控制 b.com 的 extension)。
若想了解更多:
V8 APIs
//v8/include/v8.h 中定义了很多 V8 API。这些底层 API 很难用,platform/bindings/ 提供了一堆封装了 V8 API 的 helper class, 尽量使用 helper class 而不是直接使用 V8 API。 如果你的代码中大量地使用 V8 API, 那么你的代码应该放在 bindings/{core,modules} 里。
V8 使用句柄(handle) 指向 V8 对象。最常用的句柄即 V8::Local<> , 用来指向栈中的 V8 对象,它必须在 V8::HandleScope 之后使用,且不可以在栈外使用:
|
1 2 3 4 5 6 7 8 |
void function() { v8::HandleScope scope; v8::Local<v8::Object> object = ...; // This is correct. } class SomeObject : public GarbageCollected<SomeObject> { v8::Local<v8::Object> object_; // This is wrong. }; |
如果想在栈外使用 V8 对象, 那就需要使用 wrapper tracing, 且要注意不要循环引用。
若想了解更多:
- 如何使用 V8 API 及 helper class
V8 wrappers
每个 C++ DOM 对象都有其相对应的 V8 wrapper。准确地说,每个 C++ DOM 对象, 在每个 world 中都有其相对应的 V8 wrapper。
V8 wrapper 拥有其对应的 C++ DOM 对象的强引用,而 C++ DOM 对象只有其对应的 V8 wrapper 的弱引用。所以如果想使 V8 wrapper 在一段时间内存活,则必须显声明, 否则 V8 wrapper 会被过早回收,而其中的 JS 属性就会丢失。
|
1 2 3 4 5 6 |
div = document.getElementbyId("div"); child = div.firstChild; child.foo = "bar"; child = null; gc(); // If we don't do anything, the V8 wrapper of |firstChild| is collected by the GC. assert(div.firstChild.foo === "bar"); //...and this will fail. |
如上。为使 div.firstChild 的 V8 wrapper 存活,需要一种机制, 即:"只要可以从 V8 访问到 div 所属的 DOM 树, 就使 div.firstChild 的 V8 wrapper 存活"。
这里有两种方法来对 V8 wrapper 保活: ActiveScriptWrappable 和 wrapper tracing
若想了解更多:
- 如何管理 V8 wrapper 的生命周期:bindings/core/v8/V8Wrapper.md
- 使用使用 wrapper tracing: platform/bindings/TraceWrapperReference.md
渲染流水线
从 HTML 文件传送到 Blink,再到像素显示在屏幕上,这中间经历了漫长的过程。渲染管道的架构如下。

[这个 ppt ] 完美地呈现了渲染流水线的每个阶段的工作。
若想了解更多:
- Overview: Life of a pixel
- DOM: core/dom/README.md
- Style: core/css/README.md
- Layout: core/layout/README.md
- Paint: core/paint/README.md
- Compositor thread: Chromium graphics
参考
- 这笔记笔记翻译自 how blink works, 原文发表于2018年