场景:在某个 SQL 中,得到一个中间表 m ,需要对 m 表 进行分条件的计数运算。为提高效率,不对 m 表做持久化处理。该如何做?
简单地说,即在一条语句中查询多个 COUNT 值。
一个解决方案是求助于 CASE 表达式 与 SUM 表达式。
CASE 表达式
在 SQL 语句中, CASE 表达式 具有编程语言中的 if -- else 的功能。
|
|
CASE [base expression] WHEN w1 THEN rst_1 WHEN w2 THEN rst_2 [ELSE rst_3] END -- e.g: CASE x WHEN w1 THEN r1 WHEN w2 THEN r2 ELSE r3 END CASE WHEN x=w1 THEN r1 WHEN x=w2 THEN r2 ELSE r3 END |
关键字 CASE 与 WHEN 之间的可选表达式称为 base expression。WHEN 与 THEN组成WHEN 表达式,THEN 关键词后跟的是 WHEN 表达式的 值。还可以包括 ELSE 表达式,它是可选的
- 在不使用 base 表达式的情况下,每个 WHEN 表达式从左到右依次计算布尔值, CASE 表达式的值为第一个为 真值 的 WHEN 表达式的值。如果没有值为真的 WHEN 表达式,CASE 表达式的值为 ELSE 表达式值。如果即没有值为真的 WHEN 表达式,也没有 ELSE 表达式,即么 CASE 表达式的结果为
NULL
- 在有 base 表达式的情况下,base 表达式会且仅会计算一次,然后从左到右依次与 WHEN 表达式做逻辑运算,第一个运算结果为真的WHEN 表达式的值即为 CASE 表达式的值。如果没有匹配的WHEN表达式,那么 ELSE 表达式的值即为CASE语句的值。若连 ELSE 表达式也没有,即么 CASE 表达式的值即为
NULL
SUM 表达式
啥?
实践
注:本实践使用 sqlite。
|
|
create table tb(name TEXT, age INTEGER, sex INTEGER); INSERT INTO tb VALUES('Tom',13,1); INSERT INTO tb VALUES('Aom',13,1); INSERT INTO tb VALUES('Bom',18,0); INSERT INTO tb VALUES('Com',22,1); INSERT INTO tb VALUES('Dom',23,0); |
现在要计算出 tb 表中 1. 有多少男性,2. 有多少儿童 3. 共多少人。SQL 如下:
|
|
SELECT count(*) AS total, SUM(CASE sex WHEN 1 THEN 1 ELSE 0 END) man, SUM(CASE WHEN age < 14 THEN 1 ELSE 0 END) child FROM tb |
问题及解决办法
一个Android程序在大部分手机上运行正常,在某一款手机(华为荣耀7)上运行失败。具体表现为在写入Sqlite数据库时出现Sqlite3Exception :attempt to write a readonly database.
在仔细检查sqlite3_open/sqlite3_open_v2的参数、apk的SD卡读取权限、sqlite数据库的文件读写权限后,并没有发现任何问题,那么分析问题可能出在NDK与机器架构上了。
查看该机器使用的是arm64位CPU.然而在application.mk文件里,APP_ABI 并未配置64位选项。
配置
APP_ABI := armeabi-v7a arm64-v8a
后再使用NDK编译 ,解决sqlite3的Readonly的问题。
SQLiteAPI从功能上可以分为两部分:核心API和扩展API.
核心API用于提供基本的数据库操作,如连接数据库、处理SQL、查询结果,以及一些辅助函数如字符串格式化、调试、错误处理等。
扩展API支持用户自定义函数、聚合和排序规则。
主要数据结构
QLite有很多组件。从程序员的角度 ,我们要了解的主要有connection、statement、B-tree、pager。
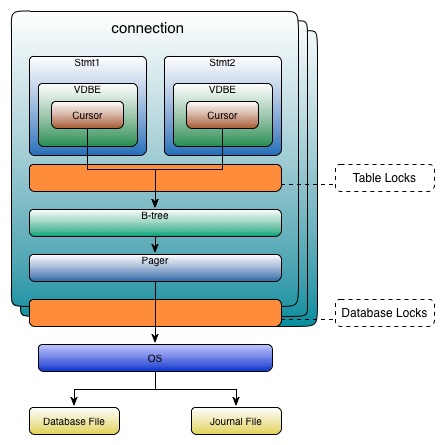
connection 和 statement
API 中,与查询处理有关的两个基本数据结构是连接和语句。在 C-API 中,它们分别对应 sqlite3 和 sqlitestmt 句柄。基本上,所有主要 API 都是在操作这两个数据结构。
一个连接对象(connection)代表数据库的连接和事务的上下文。statement来自于connection, 每个statement都有一个connection。 一个statement代表了一个编译的SQL语句。在内部,它使用VDBE来表示。statement 包括了执行一个命令所需要的一切。
B-tree 和 Pager
一个连接对象可以连接到多个数据库对象——一个主数据库和多个附加数据库。每个数据库对象都有一个B-Tree和相应的Pager对象。SQLite数据库中使用B-tree来存储表的索引和数据。statement使用B-tree的游标遍历存储在page中的记录。B-tree不直接读写磁盘,它只维护page间的关系。在游标访问page之前,pager负责将数据从磁盘中加载到页面缓存(page cache)中。
B-tree 中的页面由B-tree记录组成,也叫payloads。每个payload分两个域:关键字域(key field)或数据域(data field)。关键字域是ROWID或其它关键字的值。B-tree的任务是排序和遍历,所以关键字对其尤为重要。 如果cursor改变了page,为防止事务回滚,则pager需要保存修改前的page。
sqlite采用模块化的体系结构,可划分为3个子系统共8个模块,这些模块将查询过程分成独立的任务,像流水线一样工作。

接口
接口处于Sqlite查询工作流的起始位置,由Sqlite C API构成。应用程序由此处与Sqlite交互。
编译器
编译过程由词法分析器(Tokenizer)、语法分析器(Parser)开始,协同处理文本形式的结构化查询语句(SQL),分析其语法的有效性,然后转化为下一层能方便处理的层次化数据结构。SQL语句先被分解成一个个的词法记号,然后以语法树的形式重组,语法分析器将该树传给代码生成器。
代码生成器将语法树翻译成一种Sqlite专用的汇编代码,这些代码由一些虚拟机招待的指令组成。代码生成器的唯一工作是将语法树转换为完全由这种汇编代码编写的程序并交给虚拟机处理。
虚拟机
Sqlite架构的核心是虚拟机,也称做虚拟数据库引擎(Virtual Database Engine,VDBE)。它是基于寄存器的虚拟机,在字节码(称为虚拟机语言)上工作,使得它可以独立于操作系统、CPU和系统体系结构。虚拟机语言由100多个被称为操作码(opcodes)的任务构成。VDBE是一个专为数据处理设计的虚拟机,它的指令集中所有的指令,或者用来完成具体的数据库操作(如打开一个表的游标、开始一个事务),或者以某种方式控制栈完成这些操作做准备。这些指令以恰当的顺序组合,就可以满足复杂的SQL命令的要求。
VDBE之前的所有模块都是用于创建VDBE程序,它之后的所有模块都是用于执行VDBE程序。
后端
后端由B-Tree、页缓存(Page cache)以及操作系统接口组成。 B-Tre的职责是排序。它维护着多个页面之间的复杂关系,这些关系能保证快速定位并找到一个有联系的数据。B-Tree将页面组织成树状结构,页面是树的叶子。这些结构便于搜索。 Pager帮助B-Tree管理页面,它负责传输。pager根据B-Tree的请求从磁盘读取页面,或向磁盘写入页面。由于磁盘操作的性能有限,pager试图通过将频繁使用的页面缓存到内存中来进行加速。pager的功能还包括事务管理、数据库锁以及崩溃恢复,其中许多功能是通过OS接口实现的。
操作系统掊向上层屏蔽了不同操作系统间的差异。保证了其他模块代码的整洁,将凌乱的操作在一个地方集中管理起来,使得Sqlite可以很容易的移植到不同的操作系统上。
sqlite中支持的时间和日期函数共有 5 个:
- date(timestring, modifier, modifier, …)
- time(timestring, modifier, modifier, …)
- datetime(timestring, modifier, modifier, …)
- julianday(timestring, modifier, modifier, …)
- strftime(format, timestring, modifier, modifier, …)
上述 5 个函数,都传入时间字符串 timestring 作为参数,后面接 0 到多个modifier 修饰符。 而 strftime 将 format 作为第一个参数,对时间进行重新格式化。
timestring
可以采用以下任何一种格式:
| 序号 |
时间字符串 |
实例 |
| 1 |
YYYY-MM-DD |
2010-12-30 |
| 2 |
YYYY-MM-DD HH:MM |
2010-12-30 12:10 |
| 3 |
YYYY-MM-DD HH:MM:SS.SSS |
2010-12-30 12:10:04.100 |
| 4 |
MM-DD-YYYY HH:MM |
30-12-2010 12:10 |
| 5 |
HH:MM |
12:10 |
| 6 |
YYYY-MM-DDTHH:MM |
2010-12-30 12:10 |
| 7 |
HH:MM:SS |
12:10:01 |
| 8 |
YYYYMMDD HHMMSS |
20101230 121001 |
| 9 |
now |
2014-05-07 |
'T' 可以作为日期和时间的分隔符
modifier
- NNN days
- NNN hours
- NNN minutes
- NNN.NNNN seconds
- NNN months
- NNN years
- start of month
- start of year
- start of day
- weekday N
- unixepoch
- localtime
- utc
这些修饰符会按参数从左到右的顺序将时间进行相应的运算。
- 前 6 个修饰符可以对时间进行加减时间段的运算。如 '2 days' 表示在 timestring 的基础上再加 2 天,而 '-1 hours' 表示在前时间的基础上减一个小时。
- 'start of' 修饰符将时间转换成当月、当年、当天 有起始时间。如 'start of year' 将时间转换为 '2013-01-01 00:00:00'
- 'weekday N' 修饰符将当前时间前进到下一个星期N.(周日为星期0,周一为星期1).如今天是1月1日星期3,那么下一个星期4将是1月2日,下一个星期2将是1月8日。
- 'unixepoch' 将 10 位数字的unix时间戳转换为相应的时间字符串。
- 'localtime' 和 'utc' 将时间在格林威治时间和本地时间之间进行转换
format
格式化字符串,使用'%'进行转义
- %d 一月中的第几天,01-31
- %f 带小数部分的秒,SS.SSS
- %H 小时,00-23
- %j 一年中的第几天,001-366
- %J 儒略日数,DDDD.DDDD
- %m 月,00-12
- %M 分,00-59
- %s 从 1970-01-01 算起的秒数
- %S 秒,00-59
- %w 一周中的第几天,0-6 (0 is Sunday)
- %W 一年中的第几周,01-53
- %Y 年,YYYY
- %% % symbol
Sqlite3提供了函数
select time()
select datetime()
来获取时间和日期。不过获取出来的是世界时间。可以给函数传参数来获取本地时间:
select time(CURRENT_TIMESTAMP,'localtime');
select datetime(CURRENT_TIMESTAMP,'localtime')
R-Tree简介:
R-Tree是一种为空间查询而生的数据结构。只要给出一个空间对象的范围,使用R-Tree就可以快速而精确的查询出你所需要的空间对象(一个精确对象或是与之叠加的一组对象)。
让你的SQLite支持R-Tree
如果你使用的SQLite是从SQLite官网上直接下载的DLL文件,那么它应该已经包含了R-Tree功能模块。如果你使用的是自己定制的SQLite库,那么你在编译的时候,就需要打开R-Tree开关了(R-Tree模块默认是禁用的)。在C模式下编译的时候,添加 SQLITE_ENABLE_RTREE 宏开关,就可以获取R-Tree模块支持了。
在SQLite中使用R-Tree
构建R-Tree结构
SQLite中的R-Tree以虚表(Virtual Table)实现,最多支持5维空间索引。在N维R-Tree中,需要给出一个64位有符号整型作为索引(同时也是主键),然后给出N维的32位浮点数的空间范围值对。例如,一维的R-Tree,需要给出三个字段:索引、最小值、最大值,二维的R-Tree,需要给出五个字段:索引、X最小值、X最大值、Y最小值、Y最值…以此类推,五维的R-Tree,有11个字段。
在SQLite中创建一个R-Tree很简单,只需要一条Sql语句就可以搞定:
格式:CREATE VIRTUAL TABLE <name> USING rtree(<column-names>);
例如:CREATE VIRTUAL TABLE demo_index USING rtree(
id, -- Integer primary key
minX, maxX, -- Minimum and maximum X coordinate
minY, maxY -- Minimum and maximum Y coordinate
);
继续阅读
