最近做了一些与密码学相关的工作,对于消息的加解密有了一些新的看法。结合之前项目中遇到的服务端密码存储的问题,在这里写一点自己的想法。
目前常见的一些密码存储方式
以下是一些常见的密码存储方式,其中一部分是自己用过的,一部分是见过别人使用的:
- 明文
pwd
- 经过MD5 哈希后存储
md5(pwd)
- 两次MD5后存储
md5(md5(pwd))
- 加盐md5存储
md5(pwd + salt)
- 密码扩展后存储
kdf(pwd)
- 慢哈希后存储
brypt(pwd)
- 以上多种算法组合后存储
哈希
很明显,第 1 种是最不安全的。存储在数据库中的密码可以轻易地被管理员看到。一旦服务器被拖库,这些密码就轻易地被别人窃取,并可以根据账号和密码在其它网站上试探(大部分用户在多个网站上使用相同的用户名和密码)。尽管人人都知道这种存储方式是极不安全的,但仍然有很多网站使用它。如前几年震惊中外的 CSDN 拖库事件 。在这一事件中,有600万用户的信息被泄漏。
第 2 种 方式比较古老,管理员和黑客无法看到用户的明文密码。但如我们所知,MD5 是不安全的。如 MD5 碰撞算法。而在此之前,查表法一直做为破解 MD5 密码的重要手段 。 所谓 查表法 ,就是对字典(密码集) 进行 MD5 运算,将哈希值预存储在一个或多个表里。
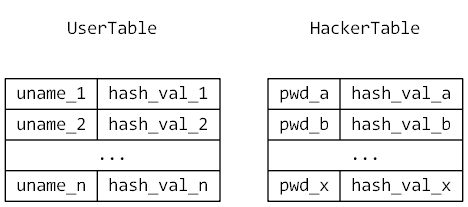
当需要破解某密码时,根据服务器存储的哈希值在预计算的哈希值表中查找对应的值。而 反向查表法 ,攻击者可以同时对多个重合密码进行攻击。
|
|
SELECT table_b.pwd, table_user.uname FROM table_user,table_b WHERE table_b.hash_val = 'hash_val_1' ; -- 查表 SELECT table_b.pwd, table_user.uname FROM table_user,table_b WHERE table_user.hash_val = 'hash_val_x' ;. --反向查表 |
如果用户使用了弱密码,这种使用反向查表法来破解密码简直不要太轻松。
使用查表法需要存储字典与哈希值,对存储空间有较高的要求。后来进化出了 彩虹表 法,在算法的空间和时间上进行了优化。
加盐
第 3、4 种方式针对上述攻击方法做了改进。其实第 3 种方式并大的改进, 因为算法和参数是固定的。而第 4 种的改进比较好。所谓 加盐(salt) ,即在消息的任意固定位置添加附加消息。它使攻击者的字典变得更加复杂,攻击者计算预存储值的难度大大增加了;每个密码都混入了不同的盐,所以使得反向查表法去批量匹配密码变得难以施行。在加盐存储的实践中,有部分人使用了错误的实现:如盐值过短,或盐值重复。
盐值过短 无法对攻击者造成足够的困扰,一个好的盐值的长度起码要和哈希值的长度一至。而 盐值重复 则和未加盐没有区别:两个相同的密码加相同的盐,得到的哈希值是一样的。特别是对于那些将盐值硬编码到代码里的,简直是在为攻击者提供帮助。类似地,也不要使用用户名、用户id、创建时间等字段做为盐值--盐值应该是随机的,且并用户修改密码时应该给出新的盐值。
继续阅读
这里总结了JavaScript中常见的数据类型转换
1 字符串 to 数值
显式转换
通常的做法是使用 Number(),parseInt() , parseFloat() 函数。需要注意的是, Number() 的参数不能含有非数字字符串值 ,如 Number(100x) 会得到 Nan, 而 parseInt(), parseFloat() 则是参数的第一个字符不可以是非数字,否则会得到 Nan, 而且它会忽略第一个非数字的字符串之后的所有字符。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
js>Number<('100x') NaN js>parseInt('100x') 100 js>parseFloat('100x') 100 js>parseInt('10d20x') 10 js>parseFloat('10d20x') 10 js>Number('10d20x') NaN js>parseInt('a10d20x') NaN js>parseFloat('a10d20x') NaN js>Number('a10d20x') NaN |
对于 parseInt() 函数来说,可以指定进制。早期版本的 JavaScript 默认执行 8 进制转换,而新版本使用 10 进制 进行转换。如果需要保证兼容性,则需要带上第二个参数:
|
|
js>parseInt('11',2) 3 js>parseInt('11',3) 4 js>parseInt('11',4) 5 js>parseInt('11',8) 9 js>parseInt('11',10) 11 js>parseInt('11',16) 17 |
隐式转换
数值的字符串变量(指可以通过 Number函数转换为数值的字符串,本节中的字符串均指可以通过 Number() 转换为数值的字符串) 在遇到数值运算符时可能发生隐式转换:
继续阅读
gyp 官网
Generate Your ProjectsGenerate Your Projects (可能需要梯子)
gyp 命令
--depth 据说是Chromium历史遗留问题,需要设置为 --depth=.-f 指定生成工程文件的类型,选项有: make ninja xcode msvs scons-G 指定 vs 版本 msvs_version=2013-D 传入变量到 gyp。传入的变量可以在gyp内使用 <(VAR) 获取--toplevel-dir 设置源代码的根目录,默认为depth设置的目录
执行 shell 命令
gyp 可以将 shell 命令的结果返回给变量,语法为 <!(cmd) 或 <!@(cmd) ,前者返回 string ,后者返回 list.
如使用 ls 命令在 source 中添加所有的 .h 文件 :
|
|
'source': [ '<!@(ls -l ./*.h)', ] |
常用配置项
defines 宏定义 ,对应 -D ,如 -D_DEBUGinclude_dirs 头文件地址, 对应 -Icflags 编译选项, 如 -g -O3ldflags 链接选项, 对应 -l ,如 -lpthread -lsqlite3type 目标类型 有 executable ,static_library ,shared_library
变量
变量分为两类,预定义变量、自定义变量
预定义变量
这些变量名称为gyp内置,一般为 大写或(或)下划线 组成:
OS 操作系统,如 OS == "win"EXECUTABLE_PREFIX 可执行文件的前缀EXECUTABLE_SUFFIX 可执行文件的后缀PRODUCT_DIR 编译出的目标文件的目录INTERMEDIATE_DIR 中间文件目录(只对单一 target 有效)
自定义变量
variables 用于自定义变量。自定义的变量可以使用以下方式使用:
继续阅读
1 字节顺序
鸡蛋有几种吃法?也许你从未注意。Jonathan Swift 的小说 Gulliver's Travels 描写了这么一个故事: Lilliput 国的皇帝因按古法打鸡蛋时弄破的手指,于是下令全体臣民吃鸡蛋时必须先打破鸡蛋较小的一端(little-endian)。但百姓这对项命令本极度反感,并为此发动叛乱。
在计算机时代,计算机网络的开创者之一, Danny Cohen 开始使用 Swift 的小说中的词语 大端、小端 来描述字节的顺序,大小端这一术语开始被人们所接纳。 在计算机时代的远古时期,计算机刚被发明的时候,由于不能统一规则,对多字节对象在存储器上的存储方式有两种不同的方式。但它们有一个共识,即,多字节的对象都被存储为连续的字节序列,而对象的地址则这段连续序列中的最小的字节的地址。
例如,一个 int 类型的变量 n 的地址为 0x100,即 &n == 0x100,那么 n 将被存储在 0x100,0x101,0x102,0x103 这段位置。 假定有一个 w 位的整数,其 位 表示为 [bw-1, bw-2, … ,b1, b0] , 其中 bw-1 为最高位,b0 为最低位。这些位按每 8 位,即一个字节分组, 表示为 [Bx-1, Bx-2, … , B1, B0] ,其中 Bn = [bn*8-1, bn*8-2, … , bn*8-8] 。 有的机器选择选择在存储器按照从低字节到高字节的顺序来存储,这种方式称为 小端法(little-endian) ,基本所有的 Intel 机器都采用这种方式。而别一部分机器则选择按照高字节到低字节的方式来存储,称为 大端法(big-endian) ,大部分 IBM 和 Sun 的机器都采用这种规则。
所以,当一段数据从使用小端规则的机器传送到使用大端规则的机器上时,数据是无法正确解析的。除非明确的告诉计算机,这段数据需要使用哪种规则来解析。这计算机网络发明以后,这种不兼容的带来的负面作用显得尤为突出。于是一个规则产生了,在网络传输过程中,数据的发送方必须将多字节数据转换成大端法表示后再发送。而数据的接收方则需要按照大端法来解析多字节数据,再转换为它的内部表示。这样,在网络中,终端只关心本机的字节序与网络字节序,而不用关心网络另一端的机器使用什么样的字节充。所以又将大端法称为 网络字节序 ,以区分 本机字节序 。
继续阅读
子模块 (Submodule)
添加
git submodule add [remotegiturl] [localdir]
更新
git submodule update --init --recursive
clone 时更新子模块
git clone [remotegiturl] --resuresive
远程更新(更新到最新)
submodule 不会detach到源的任何一个分支,而只是源的某一个commit,
使用 git submodule update --remote
将本地的子模块更新到最新。如果需要将远程仓库的子模块了更新到最新,可以先更新本地,再push到远程仓库:
|
|
git add . git commit -m "submodule update" git push |
删除
git 没有提供删除子模块的命令
继续阅读
TCP(TRANSMISSION CONTROL PROTOCOL,即传输控制协议)
是当今网络中使用得最为广泛的协议。与 UDP不同,TCP 提供了一种 面向连接(connection-oriented) 的、可靠的字节流服务。"面向连接",是指使用 TCP 的两个应用程序 必须在它们可以交换数据之前,通过相互联系建立起一个 TCP 连接。建立起连接的两端称为两个 端点(endpoint) 。因为 TCP 是面向连接的,所以像广播和组播这样的概念在 TCP 中是不存在的。 TCP 提供了流的概念,应用程序可以将任意大小的数据交给 TCP而不用关心如何发送。如,一个应用程序在一端先后写入 10 个字节、20个字节、50个字节的数据,连接的另一端的应用程序是不需要关心这个过程的,应用程序可以选择自己读取数据流的大小,如一次读20字段分4次读取,也可以一次读入80个字节。
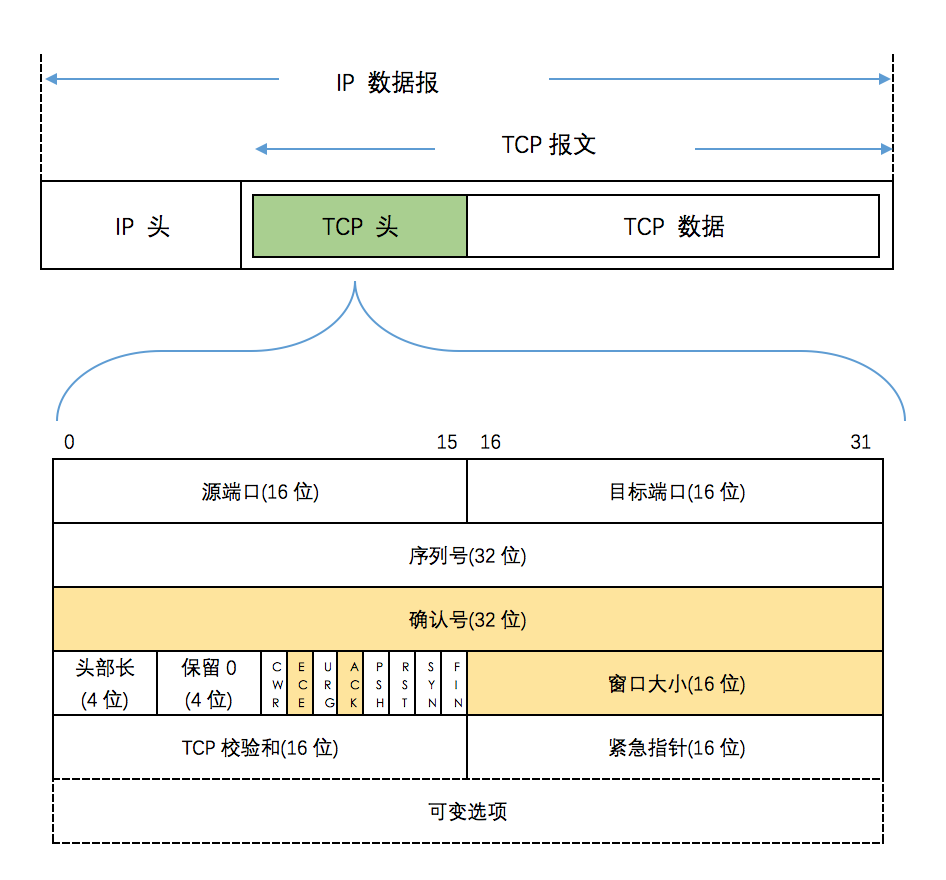
一个 TCP 块包含了 TCP头和应用程序数据,称之为 报文段(segment) 。TCP 是依赖于 IP 协议的,TCP 必须将报文段转换成一个 IP 可以携带的分组,这被称为一个 组包(packetizition)
如图,显示了 TCP 在 IP 数据报中的封装,以及 TCP 头部的结构。其中,着色部分用于与该报文的发送方关联的相反方向上的数据流。
- 端口号 每个TCP 头包含了源和目标的端口号,这两个值与IP头部的源和目标IP地址一起组成了唯一标识。一个IP与一个端口的组合被你为一个 端点(endpoint) 或一个 套接字(Socket) ,每一个TCP连接由一对套接字唯一标识。
- 序列号 字段标识了TCP发送端到接收端的数据流的字节数,代表着该报文段的数据中的第一个字节。它是一个32位无符号数,到达 232-1后再循环到0. 使用序列号,TCP的接收端可以丢弃重复的报文,并归整以杂乱次序到达的报文。TCP接收到报文的顺序是不可控的,然而TCP是一种流协议,它不能向程序程序提供顺序错乱的数据,因此,TCP接收端在向上层提供数据时,会等待较小序列号的报文,并对报文进行排序。
- 确认号 可以认为,TCP 发送的数据的每一个字节都已被编号。当TCP接收到另一端发送的数据时,它会发送一个确认。但这个确认可能不会立即发出。当接收方向发送方确认接收时,确认号表示发送言期望收到的下一个报文的序列号。所以确认号应该为
序列号 + 收到的数据的字节数据 + 1 。确认号字段只有在ACK字段启用后才有效。TCP使用确认是积累的,可以认为,一个确认号 N 表示 N-1 个字节已经被成功接收。
- 头部长度 字段给出了头部的长度,以32位字为单位。该字段只有4位,那么它能表示的最大头部长度为 60 字节。(
(2^{4}-1) * 32 / 8)。即一个TCP报文的头部长度的范围为 20 ~ 60 字节。
- 窗口大小 字段用来控制流量。该字段以字节为单位,因为它是 16 位的,故限制了窗口大小为 65535 字节,从而限制了 TCP 的吞吐性能。
- TCP校验和 字段由发送方计算和保存,由接收方校验。它用于检测传送过程中的比特差错。如果一个报文的校验和无效,那么TCP会丢弃它而不会返回任何确认信息。然而TCP可能会对一个已经确认过的报文再次确认,以帮助发送方计算它的拥塞控制。
- 紧急指针 字段只有在URG字段设置时才有效。它表示从报文的序列号开始的一个 正偏移 ,用以产生紧急数据的字段一个字段的序列号。
- 选项 是可变的。最常见的选项是 “最大段大小” 选项(MSS),连接的每一个端点一般在它发送的第一个报文上指定该选项(即设置SYN位字段的那个报文),指定该选项的发送者在相反方向上希望接收到的报文段的最大值。
- 标识位
- CWR: 拥塞窗口减(发送方降低它的发送速率)
- ECE: ECN 回显(发送方接收到了一个更早的拥塞报告)
- URG: 紧急(紧急指针字段有效)
- ACK: 确认(确认号字段有效)
- PSH: 推送(接收方应该尽快给应用程序传送这个数据 —然而没有被可靠实现或用到)
- RST: 重置连接(连接取消,经常是因为错误)
- SYN: 用于初始化一个连接的同步序列号
- FIN: 结束向对方发送数据
当TCP发送一组报文段时,通常会设置一个重传计时器,等待对方确认接收。当对方的确认报文到达时,该计时器会被更新,如果确认没有及时到达,这个报文就会被重传。 TCP提供了一种可靠、面向连接、字节流、传输层的服务。在接下来,我们将对TCP的细节进行研究。
 2015年9月17日左右,知名程序员唐巧发布微博声称Xcode有可能被第三方代码注入,而在社交平台上引起轩然大波。乌云网后续发布相关的知识库文章。而在此之前,腾讯安全应急响应中心在跟踪某app的bug时发现异常流量,解析后上报了
2015年9月17日左右,知名程序员唐巧发布微博声称Xcode有可能被第三方代码注入,而在社交平台上引起轩然大波。乌云网后续发布相关的知识库文章。而在此之前,腾讯安全应急响应中心在跟踪某app的bug时发现异常流量,解析后上报了