一、技术债务的AI困境:效率剪刀差加剧
生成式AI的普及正在技术领域制造显著的"效率剪刀差"现象。在技术债务低于警戒线的代码库中,AI工具可提升40%以上的开发效率,这种增效作用如同代码加速引擎。但当面对以下特征的遗留系统时,AI的赋能效果往往呈现出断崖式下跌的现象:
- 混沌架构:超过3层的嵌套控制流、环状依赖关系
- 暗盒逻辑:缺乏文档的定制化框架、魔数遍布的业务规则
- 脆弱基座:存在历史补丁超过原始代码量的核心模块
这种技术鸿沟导致企业陷入双重困境:新项目因AI加持加速迭代,而旧系统维护成本却指数级增长。某金融科技公司的实践数据显示,其新微服务模块开发周期缩短至2周,而核心交易系统的AI辅助成功率不足15%。
二、AI友好型架构的构建方法论
1. 模块解耦三原则
- 功能原子化:每个模块代码量控制在500行内,实现单一职责
- 接口契约化:定义强类型的输入输出规范,形成机器可读的API文档
- 依赖可视化:使用架构图谱工具自动生成模块关系图
2. AI协作增强策略
- 建立"AI训练沙盒",用典型业务场景的代码片段训练定制化模型
- 实施注释驱动开发(ADD),要求开发者用结构化自然语言描述代码意图
- 创建技术债务热力图,优先对高频修改区域进行架构改造
继续阅读
TL;NR
在 Blink 上开发绝非易事。对于新接触 Blink的开发者来说,要实现一个高效的渲染引擎,需要了解大量Blink特有的概念和编码约定。对于经验丰富的开发者来说亦非易事,因为 Blink 非常庞大,对性能、内存和安全性极为敏感。
本文从全局概述了 "Blink 是如何工作的",希望有助于开发者快速熟悉Blink的架构:
- 本文并非Blink详细架构与编码规范的开发手册(这些内容可能会变化或过时)。相反地,本文简明扼要地介绍了短期内不会变更的Blink基本原理,并提供了可以进一步阅读的资源(如果你想了解更多的话)
- 本文不解释特定功能(e.g. ServiceWorkers, editing),相反地,本文解释了代码中广泛使用的基本功能(e.g. 内容管理, V8 APIs).
关于Blink开发的更多内容, 参考这里 Chromium wiki page
继续阅读
译注:本文翻译自 ChromeDeveloper 博客, 原文发表于2018年底, 部分特性可能与目前 Chrome 有所不同。建议有条件的读者直接阅读原文。
本章是深入理解现代浏览器系列四章中的第后一章, 研究如何处理我们的代码并显示网页。之前的几章中, 我们研究了渲染进程,并了解了合成器。本章我们将研究当用户输入时,合成器如何实现与用户的流畅交互。
当说到"输入事件(input events)" , 你可能只会想到在文本框输入字符或点击鼠标,但以浏览器的视角来看,输入意味着用户的任何手势(gesture)。鼠标滚动是,触摸(touch)是, 鼠标悬停也是。
当用户触摸屏幕时,浏览器进程是首先接收到该手势的进程。但是, 因为标签内的内容是由渲染器进程处理的,browser 进程只知道该手势的位置。所以浏览器进程将事件类型(如 touchstart ) 和其坐标发送给渲染器进程。渲染器进程通过查找事件目标及运行其附加的事件监听器来适当地处理处理事件。
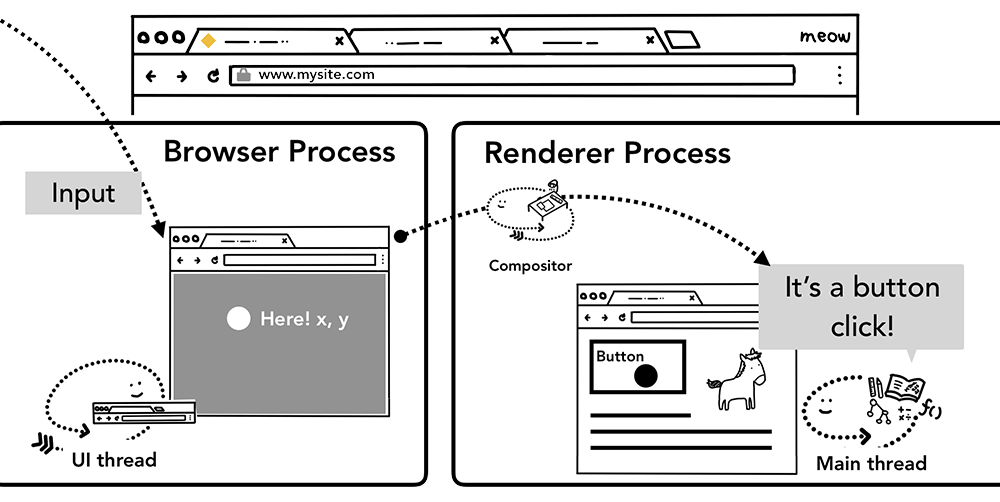
通过浏览器进程路由到渲染器进程的输入事件
继续阅读
译注:本文翻译自 ChromeDeveloper 博客, 原文发表于2018年底, 部分特性可能与目前 Chrome 有所不同。建议有条件的读者直接阅读原文。
本章是该系列4章中的第3章。之前我们研究了多进程架构和导航流程。在此章中, 我们将渲染进程内部发生了什么
渲染进程涉及到web性能的方方面面。由于渲染进程内部做了太多工作, 本章只做一个总体概述,如果你想深挖,the Performance section of Web Fundamentals 里有更多的资源。
渲染进程处理 web 内容
渲染进程负责处理标签内的一切。在渲染进程中, 主线程处理你发送给用户的大部分代码。如果你使用 web worker 或 service worker, 有时部分 JavaScript 代码由 worker 线程处理。合成器(compositor) 和栅格(raster)线程也在渲染进程内运行,以高效流畅地渲染页面。
渲染进程的核心工作是将 HTML,CSS 和 JavaScript转换为可与用户交互的网页。
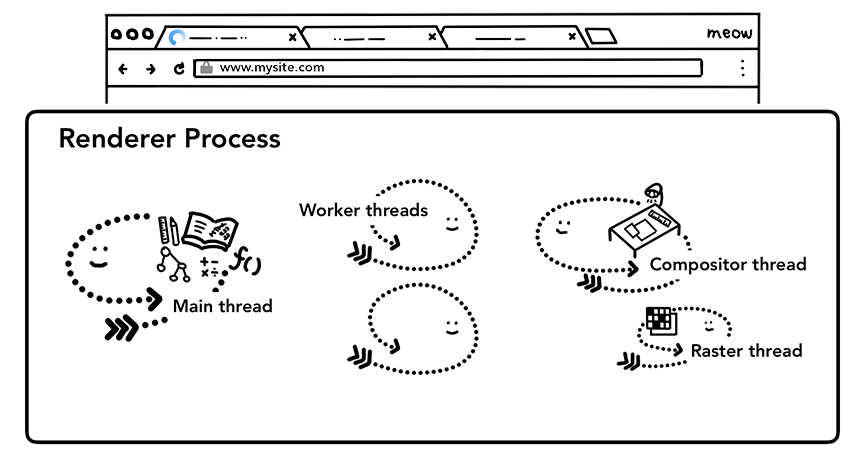
渲染进程中的主线程、worker 线程等
解析
DOM的构建
当渲染进程接收到导航的提交消息, 并开始接收 HTML 数据时, 主线程开始解析文本字符串(HTML)并将其转换为 DOM(Document Object Model).
DOM 是浏览器对页面的内部表示,也是 Web 开发人员可以通过 JavaScript 与之交互的数据结构和 API。
将 HTML 文档转换为 DOM 的解析行为由 HTML 标准定义。你可能已经注意到了, 向浏览器塞入 HTML 从来不会引发错误。比如缺少 </p> tag 的HTML是有效的 。像 Hi! <b>I'm <i>Chrome</b>!</i> (b tag 在 i tag 之前关闭)这样的错误标记会被当作 Hi! <b>I'm <i>Chrome</i></b><i>!</i> 。 这是因为 HTML 规范旨在优雅地处理这些错误。如果你感到好奇, 你可以阅读 "An introduction to error handling and strange cases in the parser" 关于 HTML 的部分。
继续阅读
译注:本文翻译自 ChromeDeveloper 博客, 原文发表于2018年底, 部分特性可能与目前 Chrome 有所不同。建议有条件的读者直接阅读原文。
本文是深入理解现代浏览器4章中的第2章。此前我们研究了不同进程和线程是如何处理浏览器的不同部件的, 本章中, 我们来深挖每个进程和线程间是如何通信以显示网站的。
我们来看一个简单浏览器网站的用例:在浏览器中输入URL, 然后浏览器从网络上获取数据并显示页面。本章中, 我们聚焦于用户请求站点并准备呈现页面这一部分--即我们说的导航(Navigation)。
从浏览器进程开始说起

browser 进程
如我们之前所说,标签以外的所有内容都由 browser 进程处理。browser 进程拥有很多线程, 像绘制按钮和输入域的 UI 线程,和网络栈交换信息以从网上接收数据的 network 线程,控制文件访问的 storage 线程等等。当你在地址栏输入URL时, browser 进程的 UI线程会处理你的输入。
简单的导航
Step 1: 处理输入
当用户开始在地址栏中输入时,UI线程首先会问"这是一搜索查询还是URL"。 在Chrome 中, 地址栏也是搜索输入域,所以UI线程需要解析并确认是使用搜索引擎还是请求站点。
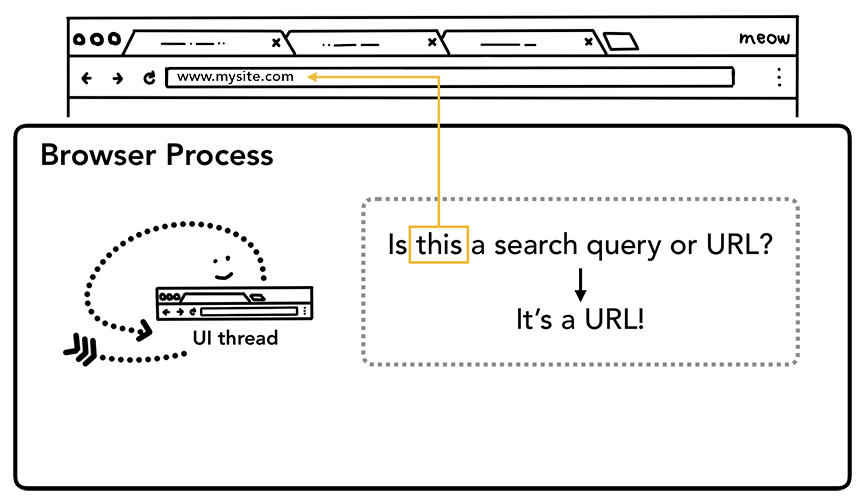
UI 线程询问输入的是搜索还是 URL
Step 2: 开始导航
当用户点击回车,UI 线程启动一个网络调用并获取站点内容。标签的左上角会显示加载动画,并且 network 线程这通过适当的协议来处理请求, 如 DNS查找与TSL连接建立。
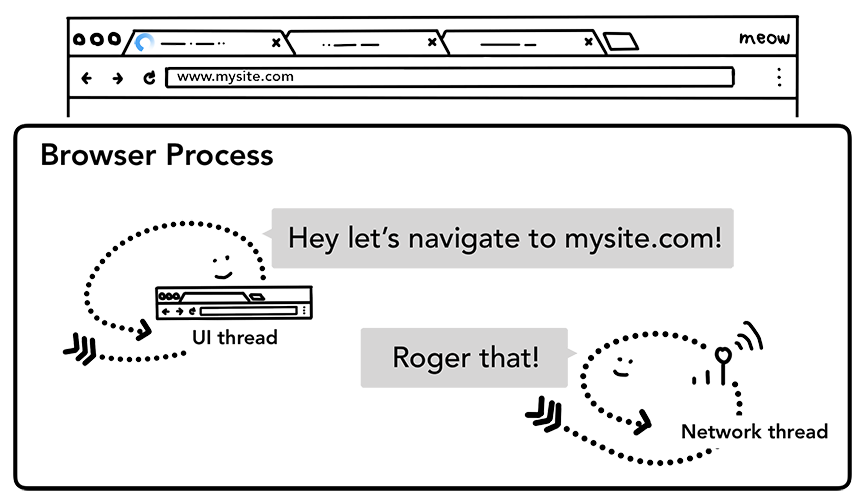
UI 线程告诉 network线程, 要导航到 mysite.com
此时, network 线程可能收到像HTTP301 这样的服务重定向头。这种情况下, network 线程和UI线程交流, 服务请求重定向, 之后开始另一个URL请求。
继续阅读
译注:本文翻译自 ChromeDeveloper 博客, 原文发表于2018年底, 部分特性可能与目前 Chrome 有所不同。建议有条件的读者直接阅读原文。
本系列有4章, 我们将从高层架构到管道渲染的细节来深入理解 Chrome 浏览器。如果你想知道浏览器如何将你的代码变成功能性的网站, 或者你不确实为何被建议使用某种技术来提高网页性能, 那么本系列会适合你。
在本章中, 我们将了解核心计算的术语及Chrome 的多进程架构。
计算机的核心是 CPU 和 GPU
为了理解浏览器运行的环境, 我们需要理解一些计算机部分及它们的作用。
CPU

首先是 中央处理单元(CPU) , CPU可以比作你计算机的大脑。一个CPU核心,就如图中的一个办公室职员, 可以一一处理很多不同的任务。它可以处理从数学到文艺的所有的事件, 甚至知道如何答复客户。过去大部分CPU是单芯的。而核就像生活在同一个CPU中的另一个芯片。在现代硬件中,你通常拥有多核CPU,它为你的手机和笔记本提供更多算力。
GPU
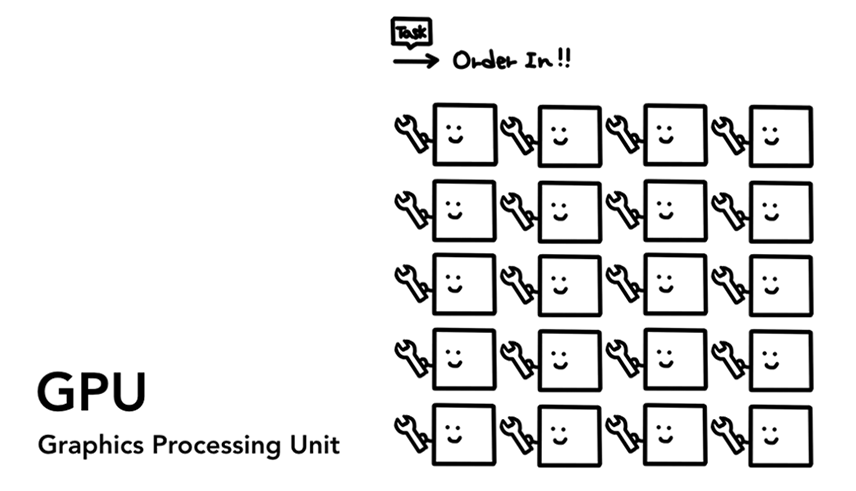
图像处理单元(GPU) 是计算机的另一个部件。和CPU不同的是,GPU擅长处理简单任务, 不过它可以同时跨越多核。顾名思义, 它最初是为处理图像而开发。这就是为何在图形上下文中, "使用GPU" 或 "GPU支持" 往往与快速渲染和平滑交互相关联。现如今, 随着GPU加速运算的发展,越来越多仅在GPU上完成的运算成为可能。
当你在电脑或手机上启动程序时, CPU和GPU都为程序提供算力。通常程序使用操作系统提供的机制在CPU和GPU中运行。
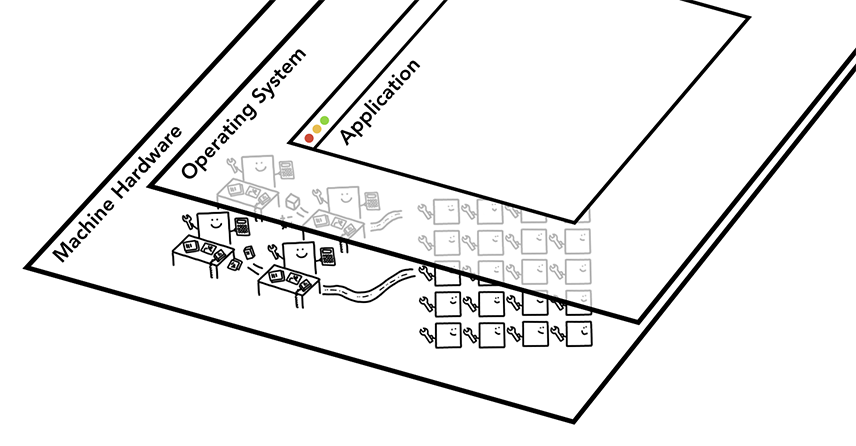
在进程和线程中执行程序
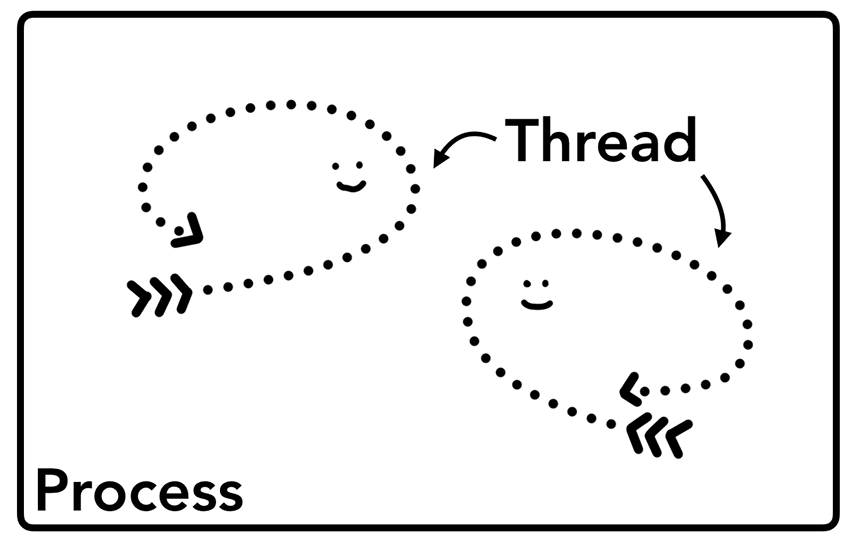
在深入研究浏览器架构之前要掌握的概念是进程和线程。进程可以看作是应用程序的执行程序。而线程存在于进程内部执行其进程程序任意部分。
继续阅读
在前一部分(从单例模式谈起(一))我们讨论单例模式时,谈到了 Double-Checked Locking 问题。我们讲, volatile 关键字并不能解决Double-Checked Locking 问题。这一节我们讨论与此相关的问题。
现代编译器为了提高程序的效率而对代码做了很多优化。这些优化大部分是有益的,但是也为多线程编程带来问题。
寄存器缓存
我们来看如下代码:
|
|
x = 0; Thread1 { lock(); x++; unlock(); } Thread2 { lock(); x++; unlock(); } |
x++ 的值有锁保护,所以它是独占的,x++ 的行为不会被并发破坏。那么 x 的值必然为 2。 然而现实中并非一定如此:编译器有可能为了提高 x 的访问速度而将 x 放入线程的某个寄存器中,而线程的寄存器是线程私有的。 如果 Thread1 先获得了锁,那么程序的执行过程有可能是这样的:
- [Thread1] 读取 x 到寄存器 R1. (R1 = x = 0)
- [Thread1] R1++. unlock. 由于之后可能还会访问 x, 所以 Thread1 不将 R1 写回 x . (x = 0)
- [Thread2] 读取 x 到寄存器 R2 (R2 = x = 0)
- [Thread2] R2++
- [Thread2] 将 R2 写回 x (x = R2 =1)
- [Thread1] 在某个时候将 R1 写回 x (x = R1 = 1)
由此可见,即使正确的加了锁,也不能保证多线程安全。
继续阅读
什么是 Coredump
coredump 核心转储 ,也称为 核心文件(core file) 是操作系统在进程收到某些 信号 而终止运行时,将此进程的地址空间以内容以及有关进程状态的其他信息写出的一个文件。这种信息往往用于调试。
程序员可以通过工具来分析程序运行过程中哪里出错了:Windows 平台用 userdump 和 WinDBG ,Linux 平台使用gdb, elfdump, objdump 等
Windows WinDBG
关于 windbg, 可以参考以下资料
Linux GDB
有些时候进程在crash的时候会产生 core 文件, 但我们却找不到 core 文件,我们需要使用 ulimit 进行一些设置, 这个命令是用来限制系统用户对shell资源的访问的。
ulimit -a 可以查看当前的设置
ulimit -c 可以设置 core 文件的上限,单位为区块(一般 1 block = 512 bytes) .其值为 0 时不写入 core, 为 unlimited 时不限制 core 文件大小。
需要注意, ulimit 只对当前会话有效。若想对所有会话生效, 需要在 /etc/profile 中进行配置。
源文件如下 test_vec.cpp :
|
|
#include <iostream> #include <vector> using namespace std; int main(){ std::vector<int> v{42}; cout<<v.at(5)<<endl; //Will crash, and coredump return 0; } |
编译运行时可能出现如下现象:
|
|
$ g++ -o t_vec ./test_vec.cpp $ ./t_vec terminate called after throwing an instance of 'std::out_of_range' what(): vector::_M_range_check: __n (which is 5) >= this->size() (which is 1) Aborted (core dumped) |
使用 gdb 打开来看:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
$ gdb t_vec core Core was generated by `./t_vec'. Program terminated with signal SIGABRT, Aborted. #0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:51 51 ../sysdeps/unix/sysv/linux/raise.c: No such file or directory. (gdb) i s #0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:51 #1 0x00007fbe77c7f801 in __GI_abort () at abort.c:79 #2 0x00007fbe782d4957 in ?? () from /usr/lib/x86_64-linux-gnu/libstdc++.so.6 #3 0x00007fbe782daab6 in ?? () from /usr/lib/x86_64-linux-gnu/libstdc++.so.6 #4 0x00007fbe782daaf1 in std::terminate() () from /usr/lib/x86_64-linux-gnu/libstdc++.so.6 #5 0x00007fbe782dad24 in __cxa_throw () from /usr/lib/x86_64-linux-gnu/libstdc++.so.6 #6 0x00007fbe782d6855 in ?? () from /usr/lib/x86_64-linux-gnu/libstdc++.so.6 #7 0x000055a4f8cda08a in std::vector<int, std::allocator<int> >::_M_range_check(unsigned long) const () #8 0x000055a4f8cd9e9d in std::vector<int, std::allocator<int> >::at(unsigned long) () #9 0x000055a4f8cd9c11 in main () (gdb) |
从 gdb显示的栈信息来看,崩溃发生在 main 函数内的 vector::at 函数内,由 _M_range_check raise 。
如果我们在编译时使用了 -g 选项, 会得到更详细的信息
继续阅读