这里总结了JavaScript中常见的数据类型转换
1 字符串 to 数值
显式转换
通常的做法是使用 Number(),parseInt() , parseFloat() 函数。需要注意的是, Number() 的参数不能含有非数字字符串值 ,如 Number(100x) 会得到 Nan, 而 parseInt(), parseFloat() 则是参数的第一个字符不可以是非数字,否则会得到 Nan, 而且它会忽略第一个非数字的字符串之后的所有字符。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
js>Number<('100x') NaN js>parseInt('100x') 100 js>parseFloat('100x') 100 js>parseInt('10d20x') 10 js>parseFloat('10d20x') 10 js>Number('10d20x') NaN js>parseInt('a10d20x') NaN js>parseFloat('a10d20x') NaN js>Number('a10d20x') NaN |
对于 parseInt() 函数来说,可以指定进制。早期版本的 JavaScript 默认执行 8 进制转换,而新版本使用 10 进制 进行转换。如果需要保证兼容性,则需要带上第二个参数:
|
|
js>parseInt('11',2) 3 js>parseInt('11',3) 4 js>parseInt('11',4) 5 js>parseInt('11',8) 9 js>parseInt('11',10) 11 js>parseInt('11',16) 17 |
隐式转换
数值的字符串变量(指可以通过 Number函数转换为数值的字符串,本节中的字符串均指可以通过 Number() 转换为数值的字符串) 在遇到数值运算符时可能发生隐式转换:
继续阅读
坑1 :
在 Pypi 上有 pywin32 的页面 ,然后无法使用 pip 命令来安装它,只有到 Sourceforge 下载源码或安装程序
坑2:
如果你下载了源码,可以使用:
来自动编译安装。很不幸,我的windows上编译环境比较复杂( 有 vs2013/2015/2017)。 setup.py 在编译时抛出了各种环境错误。好在我有 mingw,使用命令:
|
|
setup.py build --compiler mingw32 |
用 mingw 来进行编译,然后被抛出错误:
|
|
win32/src/PyACL.cpp:1090:7: warning: unused variable 'pacl' [-Wunused-variable] ACL *pacl=This->GetACL(); |
那么下载安装包直接进行安装吧 🙁
坑3:
我使用的是win10 64位操作系统,使用 python2.7 环境。于是下载了 pywin32-221.win-amd64-py2.7.exe 。点击安装,下一步:
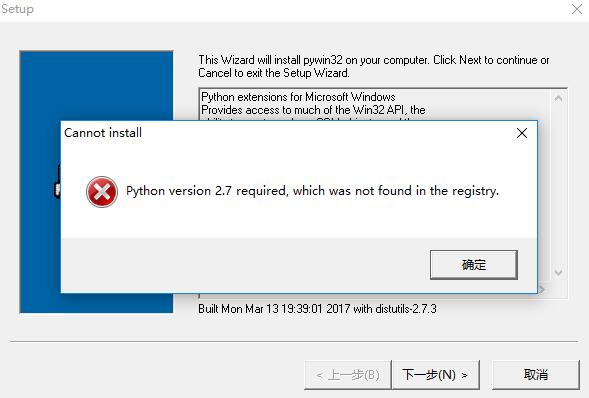
仔细检查,环境变量是没有问题的。再手动选择python安装路径(只能粘贴,不可以键盘输入),还是有错误…… 查注册表,发现注册表里有一些缺失。添加注册表:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
[HKEY_LOCAL_MACHINE\SOFTWARE\Python\PythonCore\2.7] [HKEY_LOCAL_MACHINE\SOFTWARE\Python\PythonCore\2.7\Help] [HKEY_LOCAL_MACHINE\SOFTWARE\Python\PythonCore\2.7\Help\Main Python Documentation] @="E:\\program\\Python27\\Doc\\python2713.chm" [HKEY_LOCAL_MACHINE\SOFTWARE\Python\PythonCore\2.7\InstallPath] @="E:\\program\\Python27\\" "ExecutablePath"="E:\\program\\Python27\\" [HKEY_LOCAL_MACHINE\SOFTWARE\Python\PythonCore\2.7\InstallPath\InstallGroup] @="Python 2.7" [HKEY_LOCAL_MACHINE\SOFTWARE\Python\PythonCore\2.7\Modules] [HKEY_LOCAL_MACHINE\SOFTWARE\Python\PythonCore\2.7\PythonPath] @="E:\\program\\Python27\\Lib;E:\\program\\Python27\\DLLs;E:\\program\\Python27\\Lib\\lib-tk" |
OK ,安装成功!😏
坑4:
在 python 中运行一下:
出现错误:ImportError: DLL load failed: %1 不是有效的 Win32 应用程序。
摔……😡
再次检查,发现这台电脑是安装的python 是32位 版本的。再次安装 pywin32 的32位版本,这次运行成功……
🤣
gyp 官网
Generate Your ProjectsGenerate Your Projects (可能需要梯子)
gyp 命令
--depth 据说是Chromium历史遗留问题,需要设置为 --depth=.-f 指定生成工程文件的类型,选项有: make ninja xcode msvs scons-G 指定 vs 版本 msvs_version=2013-D 传入变量到 gyp。传入的变量可以在gyp内使用 <(VAR) 获取--toplevel-dir 设置源代码的根目录,默认为depth设置的目录
执行 shell 命令
gyp 可以将 shell 命令的结果返回给变量,语法为 <!(cmd) 或 <!@(cmd) ,前者返回 string ,后者返回 list.
如使用 ls 命令在 source 中添加所有的 .h 文件 :
|
|
'source': [ '<!@(ls -l ./*.h)', ] |
常用配置项
defines 宏定义 ,对应 -D ,如 -D_DEBUGinclude_dirs 头文件地址, 对应 -Icflags 编译选项, 如 -g -O3ldflags 链接选项, 对应 -l ,如 -lpthread -lsqlite3type 目标类型 有 executable ,static_library ,shared_library
变量
变量分为两类,预定义变量、自定义变量
预定义变量
这些变量名称为gyp内置,一般为 大写或(或)下划线 组成:
OS 操作系统,如 OS == "win"EXECUTABLE_PREFIX 可执行文件的前缀EXECUTABLE_SUFFIX 可执行文件的后缀PRODUCT_DIR 编译出的目标文件的目录INTERMEDIATE_DIR 中间文件目录(只对单一 target 有效)
自定义变量
variables 用于自定义变量。自定义的变量可以使用以下方式使用:
继续阅读
1 字节顺序
鸡蛋有几种吃法?也许你从未注意。Jonathan Swift 的小说 Gulliver's Travels 描写了这么一个故事: Lilliput 国的皇帝因按古法打鸡蛋时弄破的手指,于是下令全体臣民吃鸡蛋时必须先打破鸡蛋较小的一端(little-endian)。但百姓这对项命令本极度反感,并为此发动叛乱。
在计算机时代,计算机网络的开创者之一, Danny Cohen 开始使用 Swift 的小说中的词语 大端、小端 来描述字节的顺序,大小端这一术语开始被人们所接纳。 在计算机时代的远古时期,计算机刚被发明的时候,由于不能统一规则,对多字节对象在存储器上的存储方式有两种不同的方式。但它们有一个共识,即,多字节的对象都被存储为连续的字节序列,而对象的地址则这段连续序列中的最小的字节的地址。
例如,一个 int 类型的变量 n 的地址为 0x100,即 &n == 0x100,那么 n 将被存储在 0x100,0x101,0x102,0x103 这段位置。 假定有一个 w 位的整数,其 位 表示为 [bw-1, bw-2, … ,b1, b0] , 其中 bw-1 为最高位,b0 为最低位。这些位按每 8 位,即一个字节分组, 表示为 [Bx-1, Bx-2, … , B1, B0] ,其中 Bn = [bn*8-1, bn*8-2, … , bn*8-8] 。 有的机器选择选择在存储器按照从低字节到高字节的顺序来存储,这种方式称为 小端法(little-endian) ,基本所有的 Intel 机器都采用这种方式。而别一部分机器则选择按照高字节到低字节的方式来存储,称为 大端法(big-endian) ,大部分 IBM 和 Sun 的机器都采用这种规则。
所以,当一段数据从使用小端规则的机器传送到使用大端规则的机器上时,数据是无法正确解析的。除非明确的告诉计算机,这段数据需要使用哪种规则来解析。这计算机网络发明以后,这种不兼容的带来的负面作用显得尤为突出。于是一个规则产生了,在网络传输过程中,数据的发送方必须将多字节数据转换成大端法表示后再发送。而数据的接收方则需要按照大端法来解析多字节数据,再转换为它的内部表示。这样,在网络中,终端只关心本机的字节序与网络字节序,而不用关心网络另一端的机器使用什么样的字节充。所以又将大端法称为 网络字节序 ,以区分 本机字节序 。
继续阅读
 2015年9月17日左右,知名程序员唐巧发布微博声称Xcode有可能被第三方代码注入,而在社交平台上引起轩然大波。乌云网后续发布相关的知识库文章。而在此之前,腾讯安全应急响应中心在跟踪某app的bug时发现异常流量,解析后上报了
2015年9月17日左右,知名程序员唐巧发布微博声称Xcode有可能被第三方代码注入,而在社交平台上引起轩然大波。乌云网后续发布相关的知识库文章。而在此之前,腾讯安全应急响应中心在跟踪某app的bug时发现异常流量,解析后上报了