SQLiteAPI从功能上可以分为两部分:核心API和扩展API.
核心API用于提供基本的数据库操作,如连接数据库、处理SQL、查询结果,以及一些辅助函数如字符串格式化、调试、错误处理等。
扩展API支持用户自定义函数、聚合和排序规则。
主要数据结构
QLite有很多组件。从程序员的角度 ,我们要了解的主要有connection、statement、B-tree、pager。
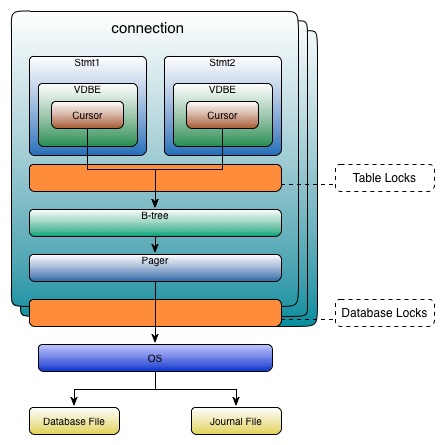
connection 和 statement
API 中,与查询处理有关的两个基本数据结构是连接和语句。在 C-API 中,它们分别对应 sqlite3 和 sqlitestmt 句柄。基本上,所有主要 API 都是在操作这两个数据结构。
一个连接对象(connection)代表数据库的连接和事务的上下文。statement来自于connection, 每个statement都有一个connection。 一个statement代表了一个编译的SQL语句。在内部,它使用VDBE来表示。statement 包括了执行一个命令所需要的一切。
B-tree 和 Pager
一个连接对象可以连接到多个数据库对象——一个主数据库和多个附加数据库。每个数据库对象都有一个B-Tree和相应的Pager对象。SQLite数据库中使用B-tree来存储表的索引和数据。statement使用B-tree的游标遍历存储在page中的记录。B-tree不直接读写磁盘,它只维护page间的关系。在游标访问page之前,pager负责将数据从磁盘中加载到页面缓存(page cache)中。
B-tree 中的页面由B-tree记录组成,也叫payloads。每个payload分两个域:关键字域(key field)或数据域(data field)。关键字域是ROWID或其它关键字的值。B-tree的任务是排序和遍历,所以关键字对其尤为重要。 如果cursor改变了page,为防止事务回滚,则pager需要保存修改前的page。
sqlite采用模块化的体系结构,可划分为3个子系统共8个模块,这些模块将查询过程分成独立的任务,像流水线一样工作。

接口
接口处于Sqlite查询工作流的起始位置,由Sqlite C API构成。应用程序由此处与Sqlite交互。
编译器
编译过程由词法分析器(Tokenizer)、语法分析器(Parser)开始,协同处理文本形式的结构化查询语句(SQL),分析其语法的有效性,然后转化为下一层能方便处理的层次化数据结构。SQL语句先被分解成一个个的词法记号,然后以语法树的形式重组,语法分析器将该树传给代码生成器。
代码生成器将语法树翻译成一种Sqlite专用的汇编代码,这些代码由一些虚拟机招待的指令组成。代码生成器的唯一工作是将语法树转换为完全由这种汇编代码编写的程序并交给虚拟机处理。
虚拟机
Sqlite架构的核心是虚拟机,也称做虚拟数据库引擎(Virtual Database Engine,VDBE)。它是基于寄存器的虚拟机,在字节码(称为虚拟机语言)上工作,使得它可以独立于操作系统、CPU和系统体系结构。虚拟机语言由100多个被称为操作码(opcodes)的任务构成。VDBE是一个专为数据处理设计的虚拟机,它的指令集中所有的指令,或者用来完成具体的数据库操作(如打开一个表的游标、开始一个事务),或者以某种方式控制栈完成这些操作做准备。这些指令以恰当的顺序组合,就可以满足复杂的SQL命令的要求。
VDBE之前的所有模块都是用于创建VDBE程序,它之后的所有模块都是用于执行VDBE程序。
后端
后端由B-Tree、页缓存(Page cache)以及操作系统接口组成。 B-Tre的职责是排序。它维护着多个页面之间的复杂关系,这些关系能保证快速定位并找到一个有联系的数据。B-Tree将页面组织成树状结构,页面是树的叶子。这些结构便于搜索。 Pager帮助B-Tree管理页面,它负责传输。pager根据B-Tree的请求从磁盘读取页面,或向磁盘写入页面。由于磁盘操作的性能有限,pager试图通过将频繁使用的页面缓存到内存中来进行加速。pager的功能还包括事务管理、数据库锁以及崩溃恢复,其中许多功能是通过OS接口实现的。
操作系统掊向上层屏蔽了不同操作系统间的差异。保证了其他模块代码的整洁,将凌乱的操作在一个地方集中管理起来,使得Sqlite可以很容易的移植到不同的操作系统上。
最近一个跨平台项目中要用到MD5算法。立马想到了大名鼎鼎的Cryptopp(Cryto++)。CryptoPP功能强大且应用非常广泛,实现了众多加密算法,被很多项目使用,如OpenSSL。于是从Cryptopp的主页下载的源码进行编译。在Windows上编译为DLL一切良好,但在Mac上为IOS编译后,发现其编译的静态库体积太过庞大,单个平台上库的体积超过20M.在多平台交叉编译,尽管使用Oz优化,.a文件仍超过了100M。因为其大量使用了模板,代码膨胀极其恐怖。这个体积给项目协作带来极大不便。所有对CryptoPP库只好忍痛放弃。
只好转向另一个实现Hash算法的库Hashlib++.该库是一个简单便捷的hash加密算法库。用其官网的话说,就是"simple and very easy to use library to create a cryptographic checksum called "hash" in C++"。
其源码在此处下载!
§§ 编译
VS新建空项目,然后加入所有源码,即可使用。但如果要编译成动态库时,就需要对源码进行改动,因为源码没有提供函数导出符号。在需要导出的类前添加 __declspec(dllexport) 修饰即可导出相应的类。
继续阅读
dotNET提供了 MD5CryptoServiceProvider 类,封装了计算MD5哈希值的相关算法。使得计算MD5相当方便。下面是使用该类计算文件MD5的一个例子:
|
|
//using System.IO; //using System.Security.Cryptography; public string ComputeMD5(string strFilePath) { if (!File.Exists(strFilePath)) return ""; byte[] btarrInfo = File.ReadAllBytes(strFilePath); MD5CryptoServiceProvider md5CSP = new MD5CryptoServiceProvider(); byte[] btarrMd5 = md5CSP.ComputeHash(btarrInfo); string strMD5 = BitConverter.ToString(btarrMd5).Replace("-", "").ToLower(); return strMD5; } |
而C++标准库中没有相应的库。相关的开源库有CryptoPP与hashlib++等开源库。可参考这里!
当我们在实现一个带有引用参数的函数时,可能会将该参数的地址存储在该函数作用域外的某个地方。如下代码所示:
MyObject* pObj = NULL;
MyObject tempObj;
void Fun(const MyObject& obj)
{
pObj = &obj;
}
tempObj.Release();
pObj.DoSomething();
当变量tempObj释放后,pObj仍保留了其地址。这将导致pObj变为空悬指针。
为了避免此类BUG出现,Mark Linton提出了如下法则:
函数中,禁止将引用参数的指针保存到函数作用域外。如果确有需要,需要将引用参数声明为指针参数
最近重新配置vsftpd后,登入ftp后出现
500 OOPS: vsftpd: refusing to run with writable root inside chroot()
根据问题提示查看了vsftpd.conf配置。
为禁止用户访问其他目录,以保证系统安全,做了如下设置:
chroot_local_user=YES
chroot_list_enable=NO
关于此配置项的具体说明可以戳这里
检查配置未发现其他问题。考虑是用户根目录的问题,将此ftp用户的根目录移动到 xx/webroot中,并在vsftpd.conf中配置此目录。问题依旧。
后查看svftpd的更新说明 ,发现从2.3.5版本以后,为保证服务器安全,根目录必须不可写。更改目录权限,解决此问题
chmod a-w xx/webroot
service vsftpd restart
在Linux上使用goagent时可能会出现该问题。
出现该问题一般是由于root用户文件夹的权限不够,一些文件无法创建。
查看 root 下是否有.pki文件夹,若没有的话则创建之。并检查文件夹的权限。最好设置为777.
chmon 777 ~/.pki/
mkdir -p ~/.pki/nssdb
certutil -d ~/.pki/nssdb -N
§前言
高精度计算是算法较为基础的一部分。
由于现有计算编程语言的数据类型限制,对于大数据的存储能力与计算能力有限。故在需要进行大数据运算时,我们采用非常规的方法代替编程语言内置的算法,来进行计算。
大数据计算的一般思路为:将大数据拆分成多个小数据,使用编辑语言能够计算的小数据进行计算,再将小数据合并成大数据。
§大数加法
从自然数的加法开始学习。
首先要解决的是数据的存储。由于C++语言的长整型存储位数有限,存储大数据会出现溢出错误,我们将大数当作一个字符串进行存储。
然后将字符串分解成可以运算的小数,按照数据运算的一般规则来进行计算处理。
最后将多个小数组合成大数表示。
则对于大数加法有如下步骤:
- 存储。使用字符串存储大数,将大数从高位到低位依次存放于字符数组中。这符合数据表示习惯
- 转换。将字符数组从低位到高位依次转换成整型数字,并按下标从大到小依次存入整型数组(即将大数据的最低位向右对齐)。这符合数据计算习惯。
- 计算。按下标从大到小(即大数据从低位到高位),依次进行单个整型的加法运算。如果满10则向高一个进1
- 转换并存储。按下标的从小到大,将整型数组元素依次存入字符数组。
继续阅读
