正则表达式
目录
正则表达式为高级的文本模式匹配、抽取、与/或文本形式的的搜索与替换功能提供基础。简单地说,它可以匹配多个字符串。
符号
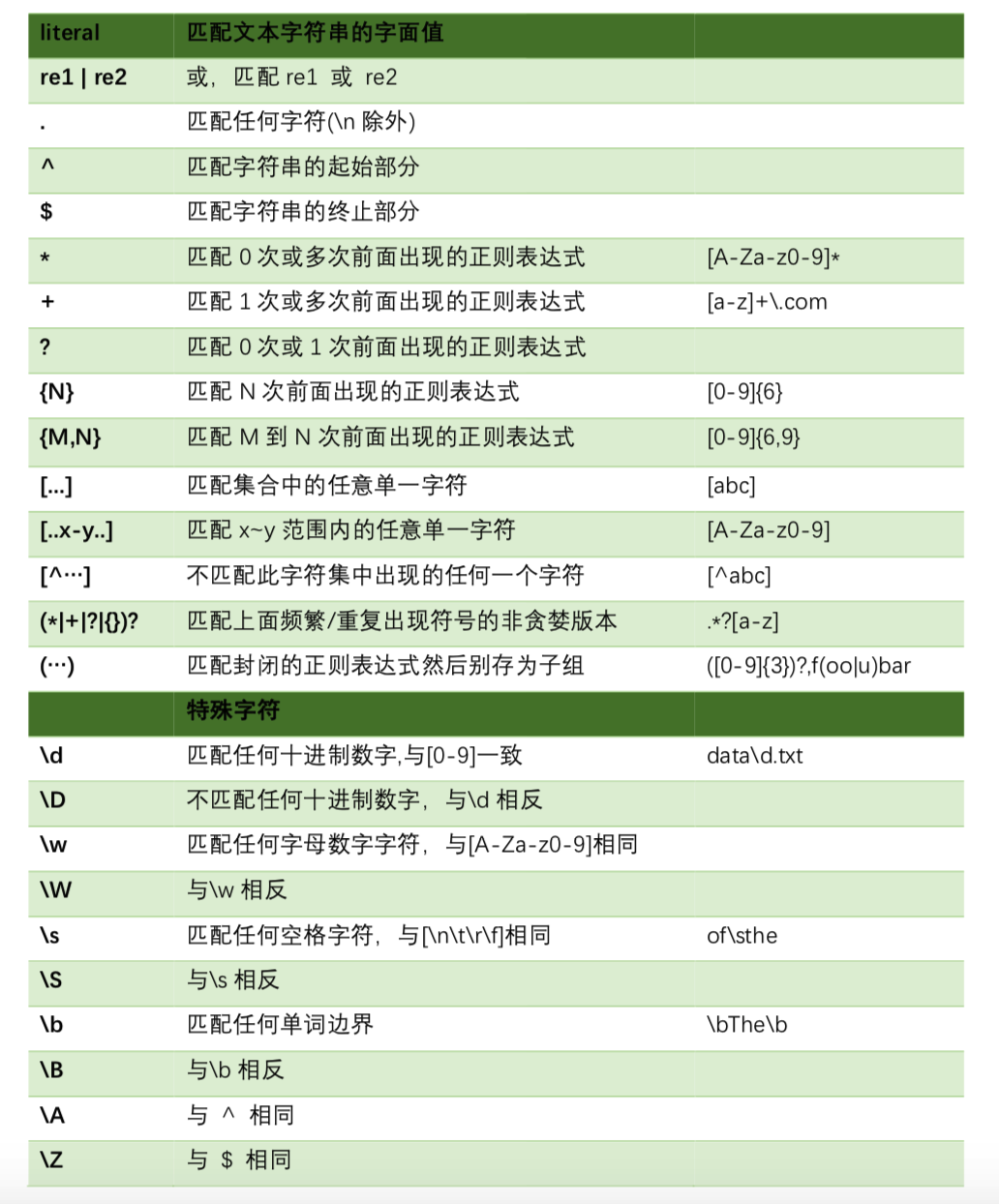
择一匹配、任意匹配
|择一匹配,表示从多个模式中选择其中一个 ,如at | home既可以匹配 at, 也可以匹配 home.任意匹配,表示匹配除了换行符\n以外的任何一个字符
边界匹配
^ $用于匹配行的开头和结尾\b用于匹配字符边界。\B则与之相反。如\bthe匹配任何以 the 起始的单词,\Bthe匹配任何不以 the 起始的单词
字符集
单一匹配
[ ]匹配某些特定的字符。 如b[au]t可以匹配 bat,也可以匹配 but. 它和b(a|u)t是等价的。需要注意的是,[ ]只能匹配单字符。如,想要同时匹配 beat bit,需要使用b(ea|i)t。该符号还有一些其它用法:
限定范围
[ ]中使用连接字符连接,用于指定一个字符的范围。如[a-zA-Z]可以匹配从 a~z,从 A~Z 的任意一个字符。如z.[0~9]用于匹配 z 后面跟一个任意字符,再跟一个任意数字。[ ]中的第一个字符如果是^,表示不匹配括号中的任意字符。 如[^0-9abc]表示不匹配任意数字,也不匹配abc中的任一个字符。
存在与频数
* + ? 三个字符,可以匹配 0 个,1 个或多个字符。
*可以匹配其左边的正由表达式出现 0 次或多次+可以匹配其左边的表达式 1 次或多次?可以匹配其左边的表达式 0 次或 1 次{ }可以控制表达式匹配的频次。如fo{2}t可以匹配 foot。若{ }中使用了,如{M,N}表示限定范围为 M~N 次。如fo{2,3}可以匹配 foot, 也可以匹配 fooot.
贪婪匹配
? 除了上述匹配 0~1 次的意义 ,存在其他含义:如果其紧跟在任何使用闭合操作符的匹配后面,它将直接要求正则表达式匹配 尽可能少 的次数。当使用了分组操作符时,正则表达式引擎会试图匹配尽可能多的字符。这叫做 贪婪匹配 。问号则要求正则表达式引擎匹配尽可能少的字符,留下尽可能多的字符给后面的模式来匹配。如 </?[^>]+> 可用于匹配任意 html 标签
指定分组
( ) 有两个功能:1.对正则表达式进行分组 2.匹配子组。
有些时候,我们可能对之前成功匹配到的数感兴趣。
(等完善)
扩展表示法 (并非所有的引擎都支持)
(?...) 圆括号内以一个问号开始,它是一种扩展表示法。它通常用于判断之前提供的标识,用于实现一个前视或后视匹配,或者条件检查。
(?:\w+\.)*以句点作结尾。如 google. ,但这些匹配不会保留焉(?#comment)不做匹配,只做注释(?=.com)如果一个字符串后面跟着 .com 才做匹配,(?!.net)如果一个字符串后面跟不是 .net 才做匹配(?<=400-)如果字符串之前是 400- 开始匹配(?<!192\.168\.)如果字符串之前不是 192.168. 才开始匹配,用于过滤 C 类 IP(?(a)b|c)如果匹配组 a 存在,则与 b 匹配,否则与 c 匹配
一些常用的正则表达式
- 合法用户名 : 由数字,下划线和26个字母组成的字符串
^\\w+$ - 密码强度 :包含大小写字母和数字的组合,不能有特殊字符,长度在8~10之间
^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$ - 只能是中文
^[\\u4e00-\\u9fa5]{0,}$ - email
^(\w)+(\.\w+)*@(\w)+((\.\w+)+)$ - 身份证号码 :15 位或 18 位
^[1-9]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}$
^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}([0-9]|X)$ - 日期 : “yyyy-mm-dd“ 格式的日期校验,已考虑平闰年
^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$ - 手机号
^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$